
TL;DR:
- HuggingFace introduces TextEnvironments, bridging ML models and Python tools for precise tasks.
- TextRL (TRL) incorporates SFT, RM, and PPO for efficient transformer language model training.
- TextEnvironments enable communication and fine-tuning of language models.
- PPO optimizes models based on reward signals, offering superior performance.
- TextRL excels in text creation, translation, summarization, and diverse tasks.
- It enhances efficiency and resilience compared to traditional approaches.
Main AI News:
In the realm of cutting-edge machine learning and natural language processing, Hugging Face has taken a significant leap forward with the introduction of TextEnvironments. These innovative TextEnvironments serve as an orchestrator, seamlessly connecting machine learning models with a comprehensive set of Python functions. This powerful combination empowers machine learning models to efficiently tackle specific tasks with precision and ease.
Supervised Fine-tuning (SFT), Reward Modeling (RM), and Proximal Policy Optimization (PPO) are all integral components of the TextRL (TRL) framework. Within this full-stack library, researchers gain access to a suite of tools designed to train transformer language models and stable diffusion models through Reinforcement Learning. This library extends Hugging Face’s renowned transformers collection, enabling the direct loading of pre-trained language models, including support for both decoder and encoder-decoder designs. To harness the capabilities of these programs effectively, consult the manual or the examples/ subdirectory for valuable code snippets and instructions.
Highlights
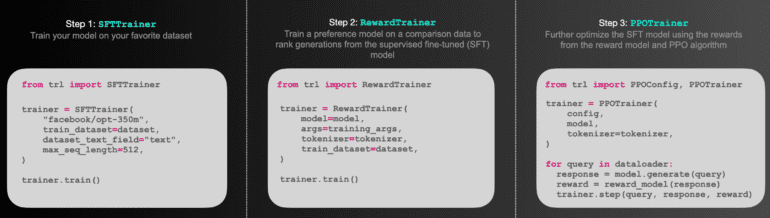
- SFTTrainer: Easily fine-tune language models or adapters on a custom dataset with the assistance of SFTTrainer, a lightweight and user-friendly wrapper built around Transformers Trainer.
- RewardTrainer: When precision and customization are paramount in modifying language models for human preferences (Reward Modeling), RewardTrainer offers a lightweight wrapper over Transformers Trainer.
- PPOTrainer: For optimizing a language model, PPOTrainer simply requires (query, response, reward) triplets, making it an efficient choice for reinforcement learning.
- Value-Enhanced Transformer Models: TextEnvironments introduces transformer models equipped with an additional scalar output for each token. These outputs can serve as a valuable tool in reinforcement learning, acting as a value function for improved performance.
- Diverse Applications: TRL opens up a world of possibilities. Train GPT2 to craft favorable movie reviews using a BERT sentiment classifier, implement a comprehensive Reinforcement Learning from Human Feedback (RLHF) system using only adapters, mitigate toxicity in GPT-j, and explore the potential of stack-llama, among other exciting use cases.
How Does TRL Work?
TextRL operates on the principle of training a transformer language model to optimize a reward signal. Expert human evaluators or specialized reward models define the nature of this reward signal. The reward model itself is an ML model designed to estimate earnings based on a specified stream of model outputs. The training process leverages Proximal Policy Optimization (PPO), a powerful reinforcement learning technique. As a policy gradient method, PPO works by iteratively adjusting the transformer language model’s policy. In essence, this policy can be viewed as a function that transforms input sequences into desired output sequences.
Using PPO, a language model undergoes fine-tuning in three primary ways:
- Release: The language model offers a potential sentence starter in response to a query or question.
- Evaluation: The evaluation phase may involve diverse factors, such as using a function, a model, human judgment, or a combination of these elements. Ultimately, each query/response pair leads to a single numeric value.
- Optimization Challenge: The most intricate part of the process involves optimizing the log-probabilities of tokens in sequences using the query/response pairs. Both the trained model and a reference model (often the pre-trained model before fine-tuning) play essential roles in this optimization. An additional reward signal, the KL divergence between the two outputs, ensures that the generated responses align closely with the reference language model. PPO is then employed to train the operational language model, resulting in enhanced performance.
Key Features
TextRL offers several distinct advantages when compared to conventional approaches to training transformer language models:
- Diverse Task Support: In addition to text creation, translation, and summarization, TextRL excels in training transformer language models for a broad spectrum of tasks.
- Efficiency: Training transformer language models with TextRL proves to be more efficient than traditional techniques like supervised learning.
- Resilience: TextRL-trained transformer language models exhibit improved resistance to noise and adversarial inputs compared to models trained using conventional approaches.
- TextEnvironments: TextEnvironments, a novel feature within TextRL, provides a set of resources for developing RL-based language transformer models. These environments facilitate communication with the transformer language model and enable the production of results that can be leveraged for fine-tuning the model’s performance. TextRL employs classes to represent TextEnvironments, offering diverse contexts such as text generation, translation, and summarization. Various projects have harnessed TextRL to train transformer language models, resulting in more creative and informative writing.
Conclusion:
TextEnvironments within the TextRL framework represent a significant advancement in the field of machine learning and natural language processing. This orchestrated connection between machine learning models and essential Python tools opens up a world of possibilities, enabling researchers to train and fine-tune transformer language models with unprecedented precision and efficiency. Harness the power of TextRL to unlock the full potential of your language models and elevate their performance to new heights.