
TL;DR:
- Researchers introduce MimicGen, an innovative technology for autonomous data generation in robotics training.
- MimicGen autonomously generates extensive and diverse datasets using a limited number of human demonstrations.
- This technology enables high-quality data across various scenarios, enhancing the training of skilled agents through imitation learning.
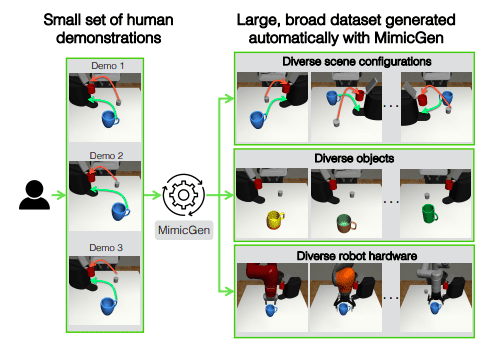
- MimicGen’s capabilities span diverse scene configurations, object instances, and robotic arms, making it ideal for various complex tasks.
- It produces over 50,000 additional demonstrations across 18 tasks with just 200 source human demonstrations.
- Comparative performance with traditional data collection methods raises questions about the necessity of more human-generated data.
Main AI News:
In the realm of robotics, training machines to perform intricate manipulation behaviors has traditionally relied on imitation learning from human demonstrations. One prevailing method entails human operators teleoperating robot arms through various control interfaces, generating multiple demonstrations of robots executing diverse manipulation tasks. The collected data is then utilized to teach robots to perform these tasks independently. Recent endeavors have sought to amplify this approach by amassing vast datasets with a more extensive pool of human operators across a broader spectrum of functions. The outcomes have been nothing short of remarkable, demonstrating that imitation learning on expansive, diverse datasets empowers robots to adapt to new objects and uncharted tasks with ease.
This underscores the significance of amassing extensive and comprehensive datasets as a pivotal initial step in cultivating versatile and proficient robots. However, the attainment of such datasets comes at a considerable cost in terms of both time and human effort. Consider a case study in which a robot’s mission is as straightforward as moving a soda can from one container to another. Surprisingly, even in this seemingly simple scenario, a substantial dataset of 200 demonstrations was required to achieve a commendable success rate of 73.3%. Recent attempts to broaden the scope to encompass various settings and objects have demanded datasets comprising tens of thousands of demonstrations. For instance, it has been demonstrated that challenges involving minor alterations in objects and objectives can be addressed with a dataset of over 20,000 trajectories.
The journey to gather this data involves multiple human operators, months of meticulous work, kitchen settings, and robotic arms—all of which culminated in a 1.5-year data-collecting endeavor by RT-1. The result: a system capable of successfully rearranging, cleaning, and recovering items in several kitchens, boasting an impressive 97% success rate. However, the exact duration required to gather sufficient data for the practical implementation of such a system in real-world kitchens remains an open question. One might ask, “To what extent does this data encompass distinct manipulation behaviors?” These datasets may encompass similar manipulation techniques employed in various settings or contexts. For instance, when grasping a cup, human operators tend to exhibit remarkably similar robot trajectories, regardless of the cup’s placement on a countertop.
The key lies in adapting these trajectories to a multitude of scenarios, enabling the generation of a diverse array of manipulation behaviors. While these approaches hold promise, they are inherently limited by their assumptions about specific tasks and algorithms. The ultimate goal is to establish a universal system that seamlessly integrates into existing imitation learning processes, elevating the performance of various tasks. In their groundbreaking research, the team introduces a novel data-gathering technique that autonomously generates extensive datasets across a plethora of scenarios, relying on only a limited number of human examples.
This innovation, known as MimicGen, dissects a handful of human demonstrations into object-centric segments, spatially modifies each segment, assembles them into a coherent whole, and guides the robot to follow this new trajectory, resulting in a fresh demonstration in a new scenario with diverse object configurations. Remarkably simple in concept, this technique has proven to be remarkably effective in generating substantial datasets spanning a wide range of scenarios, paving the way for advanced imitation learning.
The contributions of this groundbreaking research are noteworthy:
- Researchers from NVIDIA and UT Austin introduce MimicGen, a cutting-edge technology that leverages situation adaptation to create vast and diversified datasets from a limited number of human demonstrations.
- MimicGen has demonstrated its ability to produce high-quality data encompassing various scene configurations, object instances, and robotic arms—elements not present in the original demonstrations. This data empowers the training of proficient agents through imitation learning. Tasks such as pick-and-place, insertion, and interaction with articulated objects are just a few examples of the long-horizon, high-precision activities that MimicGen is ideally suited for, necessitating distinct manipulation skills. Astonishingly, using just 200 source human demonstrations, MimicGen generated over 50,000 additional demonstrations across 18 tasks, spanning two simulators and a real robot arm.
- Notably, MimicGen’s performance is comparable to the traditional approach of collecting more human demonstrations, raising crucial questions about the necessity of soliciting additional data from humans. Using MimicGen to generate an equivalent amount of synthetic data (e.g., 200 demonstrations generated from 10 human operators versus 200 human demonstrations) yields similar agent performance.
Conclusion:
MimicGen’s introduction marks a significant shift in robotics training, offering an autonomous solution that generates diverse datasets with impressive efficiency. This innovation has the potential to streamline the development of proficient robotic agents, reducing the time and resources required for data collection. As a result, it opens up new opportunities for accelerated advancements in the robotics market, making it more accessible and cost-effective for businesses to implement robotic solutions across various industries.