
TL;DR:
- NLP, a critical AI field, seeks to enhance human-computer interaction using language.
- Recent NLP research focuses on improving few-shot learning methods due to data insufficiency challenges.
- AugGPT, a novel data augmentation method, leverages ChatGPT to enhance few-shot text classification.
- AugGPT fine-tunes BERT on base datasets, generates augmented data with ChatGPT, and further fine-tunes BERT with augmented data.
- AugGPT outperforms other data augmentation techniques in classification accuracy and data quality.
- ChatGPT excels in simpler tasks and shows potential after fine-tuning, especially in complex domains like PubMed.
Main AI News:
In the dynamic landscape of Natural Language Processing (NLP), where human-computer interaction thrives through language, innovation continues to shape the field. Text analysis, translation, chatbots, and sentiment analysis are among the multifaceted applications of NLP, underpinned by the overarching goal of enabling computers to comprehend, interpret, and generate human language.
In the realm of NLP research, a persistent challenge has been the quest for improved few-shot learning (FSL) methods. As the name suggests, FSL pertains to training models to generalize effectively from a limited dataset. While advancements have been made through architectural designs and pre-trained language models, the stumbling block of data quality and quantity constraints persists.
Enter text data augmentation methods, a formidable ally in combating the limitations of sample size. These model-agnostic techniques, encompassing approaches such as synonym replacement and the sophisticated realm of back-translation, seamlessly complement FSL methods in NLP, providing a resolute solution to these pressing challenges.
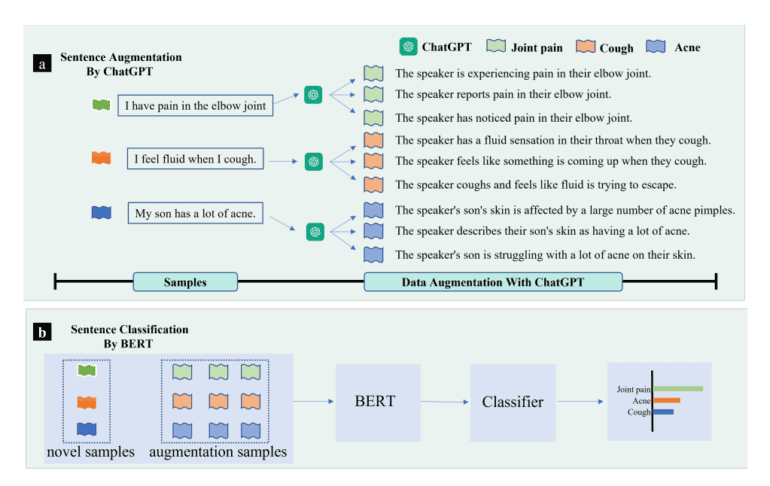
Within this context, a pioneering research team has unveiled a groundbreaking data augmentation technique dubbed “AugGPT.” This ingenious method harnesses the prowess of ChatGPT, a formidable language model, to fabricate auxiliary samples for few-shot text classification tasks.
AugGPT steps boldly into the arena of few-shot learning, where models initially trained on a source domain with meager data must ultimately demonstrate their mettle in a target domain, armed with just a handful of examples. AugGPT’s modus operandi revolves around leveraging ChatGPT to engender more samples and enhance the training data reservoir for text classification.
The crux of the AugGPT framework is a meticulously orchestrated sequence: First, the model undergoes fine-tuning with a substantial base dataset (Db) containing a generous trove of labeled samples. Next, it navigates into uncharted territory by incorporating a novel dataset (Dn) that offers only a sparse serving of labeled data. The endgame? To achieve commendable generalizability on this uncharted terrain.
AugGPT’s masterstroke unfolds through a choreography that includes fine-tuning the formidable BERT model on the base dataset, generating augmented data (Daugn) with ChatGPT, and then once more fine-tuning BERT, this time with the augmented data in tow. ChatGPT’s role is pivotal as it takes center stage in the data augmentation spectacle, ingeniously rephrasing input sentences, birthing additional sentences, and expanding the few-shot samples. The text classification model, rooted in BERT, employs cross-entropy and contrastive loss functions to wield its classification prowess.
AugGPT stands tall amidst a formidable lineup of data augmentation methods, including character and word-level substitutions, keyboard simulation, and synonym replacement. Its versatility is further highlighted by prompts meticulously designed for both single-turn and multi-turn dialogues, ensuring its efficacy across diverse datasets and scenarios.
In summation, the AugGPT approach for enhancing few-shot text classification unfurls as follows:
- Dataset Setup:
- Forge a base dataset (Db) enriched with a multitude of labeled samples.
- Craft a novel dataset (Dn) that offers just a sprinkle of labeled samples.
2. Fine-tuning BERT:
- Embark on the journey by fine-tuning the formidable BERT model on the base dataset (Db), harnessing its pre-trained language understanding capabilities.
3. Data Augmentation with ChatGPT:
- Enlist ChatGPT, the linguistic virtuoso, to weave the fabric of augmented data (Daugn) for the few-shot text classification task.
- Employ ChatGPT’s artistry to rephrase input sentences, weaving a tapestry of additional sentences and enriching the few-shot samples with newfound diversity.
4. Fine-tuning BERT with Augmented Data:
- Reengage the BERT model in the quest, this time with the augmented data (Daugn) as a trusted companion, refining it for the few-shot classification mission.
5. Classification Model Setup:
- Architect a few-shot text classification model, firmly rooted in BERT, with the augmented data as its bedrock for training.
Empirical experimentation has rendered BERT as the chosen base model for AugGPT, affirming its superiority in classification accuracy across a spectrum of datasets. AugGPT not only eclipses other data augmentation methodologies but also excels in generating high-quality augmented data, culminating in a performance boost. While ChatGPT shines brightly in less demanding tasks, a touch of fine-tuning unlocks its potential, especially in complex domains like PubMed, underscoring the value of this groundbreaking approach in elevating overall performance.
Conclusion:
The introduction of AugGPT holds immense promise for businesses, as it addresses the persistent challenge of few-shot text classification in NLP. By significantly improving classification accuracy and data quality, this innovation can lead to more effective AI-driven solutions in various industries, ultimately enhancing market competitiveness and customer satisfaction.