
TL;DR:
- FACTORCL is introduced as a novel multimodal representation learning method, addressing limitations in existing contrastive learning approaches.
- Two critical challenges are highlighted: low sharing of task-relevant information and highly distinctive data across modalities.
- FACTORCL innovatively factorizes common and unique representations and optimizes them independently, achieving a balance of relevant information.
- The method relies on maximizing lower bounds and minimizing upper bounds on mutual information, enabling self-supervised learning without explicit labeling.
- Extensive experiments demonstrate FACTORCL’s superior performance in predicting sentiment, emotions, humor, sarcasm, and healthcare outcomes across six datasets.
- Key contributions include the identification of CL limitations, the introduction of FACTORCL as a transformative contrastive learning algorithm, and its potential to reshape multimodal representation learning for real-world applications.
Main AI News:
In the ever-evolving landscape of machine learning, the quest for effective representation learning spans across various modalities. A prevailing approach involves pre-training on diverse multimodal data, followed by fine-tuning with task-specific labels—an approach that has become ubiquitous in today’s learning strategies. These multimodal pretraining techniques owe their roots to the field of multi-view learning, built on the foundational notion of multi-view redundancy, where information shared across modalities is presumed to be highly relevant for subsequent tasks. Leveraging this foundation, approaches employing contrastive pretraining have yielded impressive results in domains ranging from speech and transcribed text to images and captions, video and audio, as well as instructions and actions.
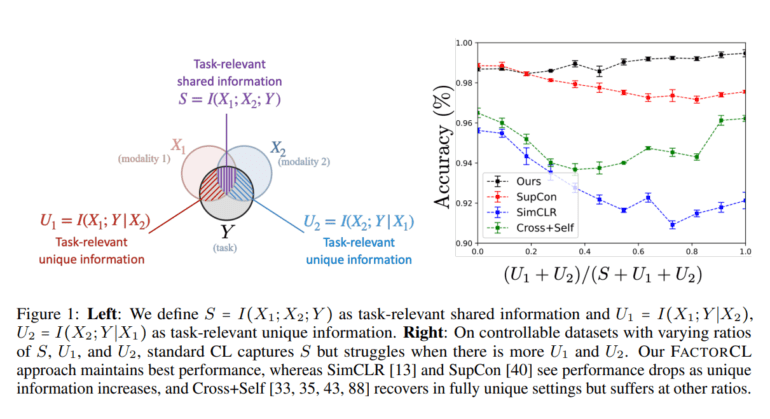
Nonetheless, a critical examination reveals two significant limitations when applying contrastive learning (CL) in broader, real-world multimodal contexts:
- Low Sharing of Task-Relevant Information: Many multimodal tasks involve minimal shared information, such as the relationship between cartoon images and figurative captions—those descriptive narratives are often characterized by metaphorical or idiomatic expressions. Under such circumstances, traditional multimodal CL methods struggle to acquire the necessary task-relevant information, ultimately grasping only a fraction of the intended representations.
- Highly Distinctive Data Pertinent to Tasks: Several modalities provide unique information not found in others. Consider the realms of robotics, where force sensors reign, or healthcare, where medical sensors hold sway. Standard CL approaches tend to disregard task-relevant unique details, resulting in suboptimal performance downstream.
The question then arises: how can we forge effective multimodal learning objectives that transcend the confines of multi-view redundancy within these constraints? In response, a collaborative effort from the academic powerhouses of Carnegie Mellon University, the University of Pennsylvania, and Stanford University introduces us to FACTORIZED CONTRASTIVE LEARNING (FACTORCL) in their groundbreaking paper. This method takes its roots in information theory, meticulously defining shared and unique information through conditional mutual statements.
FACTORCL introduces two pivotal concepts:
- Factorizing Common and Unique Representations: FACTORCL explicitly separates common and unique representations. This approach aims to create representations that strike the perfect balance, delivering just the right amount of information content.
- Maximizing Lower Bounds and Minimizing Upper Bounds on Mutual Information: The second approach involves maximizing lower bounds on mutual information (MI) to capture task-relevant information while minimizing upper bounds on MI to extract task-irrelevant information. Remarkably, FACTORCL achieves this without the need for explicit labeling, relying instead on multimodal augmentations to establish task relevance in a self-supervised learning setting.
The practical efficacy of FACTORCL is rigorously evaluated through a series of experiments, utilizing both synthetic datasets and extensive real-world multimodal benchmarks. These benchmarks encompass domains as diverse as images and figurative language, allowing for the assessment of FACTORCL’s performance in predicting human sentiment, emotions, humor, sarcasm, and even patient disease and mortality prediction based on health indicators and sensor readings. Across six datasets, FACTORCL showcases its prowess by achieving new state-of-the-art performance levels.
In summary, the key technological contributions of this paper are manifold:
- Revealing the Limitations of Typical Contrastive Learning: The research sheds light on the shortcomings of conventional multimodal CL methods when confronted with scenarios of low shared or high unique information.
- FACTORCL—A New Era in Contrastive Learning: FACTORCL emerges as a revolutionary contrastive learning algorithm, with its core innovations encompassing: (A) Factorizing task-relevant information into shared and unique components. (B) Independent optimization of shared and unique information, resulting in optimal task-relevant representations by harnessing lower limits and eliminating task-irrelevant information through MI upper bounds. (C) The integration of multimodal augmentations for estimating task-relevant information paves the way for self-supervised learning facilitated by FACTORCL.
Conclusion:
FACTORCL’s innovative approach to multimodal representation learning transcends the limitations of traditional methods, opening up new possibilities for harnessing diverse data modalities in real-world applications. This breakthrough promises to drive increased efficiency and effectiveness across various market sectors, from healthcare to robotics and beyond, by enabling more accurate and meaningful insights from multimodal data sources.