
TL;DR:
- ChatAnything: A novel framework for LLM-based persona creation.
- Customized personas with unique appearance, personality, and tones from text descriptions.
- Leveraging LLMs’ in-context learning for personality generation.
- Innovative concepts: Mixture of Voices (MoV) and Mixture of Diffusers (MoD).
- MoV uses TTS algorithms for tone selection based on text descriptions.
- MoD combines text-to-image generation with talking head algorithms.
- Challenge: Anthropomorphic objects are often undetectable by face landmark detectors.
- Solution: Pixel-level guidance for face animation based on generated speech.
- LLMs are at the forefront of academic discussions with in-context learning.
- There is a need for LLM-enhanced personas with customized traits.
- MoV module selects tones based on user text inputs.
- Visual appearance is addressed with talking head algorithms.
- Challenges with image detection are overcome by injecting face landmarks.
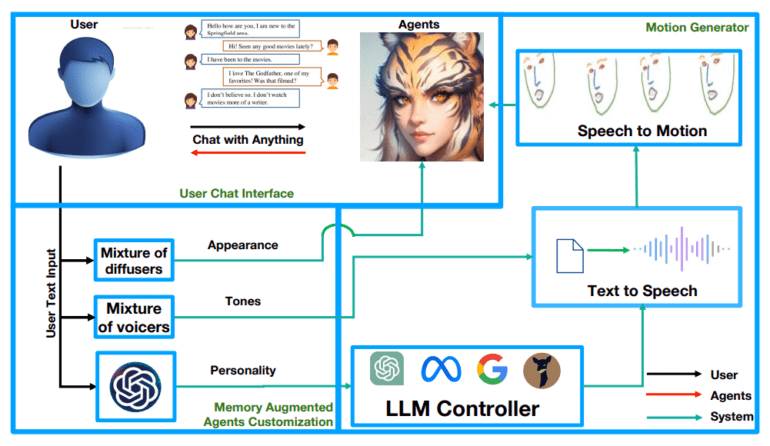
- There are four main blocks in the ChatAnything framework.
- Validation dataset showcasing the impact of guided diffusion.
Main AI News:
In a groundbreaking collaboration between Nankai University and ByteDance, a pioneering framework known as ChatAnything has emerged, poised to revolutionize the creation of anthropomorphized personas for large language model (LLM)-based characters in the digital realm. The mission? To fashion personas replete with bespoke visual attributes, distinct personalities, and unique tones, all painstakingly derived from text descriptions alone. This innovative approach capitalizes on the remarkable in-context learning capabilities of LLMs, expertly harnessing them to generate personas through meticulously crafted system prompts. Central to this novel paradigm are two ingenious concepts: the Mixture of Voices (MoV) and the Mixture of Diffusers (MoD), offering an unprecedented spectrum of diversity in voice and appearance generation.
MoV ingeniously employs text-to-speech (TTS) algorithms imbued with predefined tones, adeptly selecting the most fitting tonal quality based on user-supplied textual cues. On the other hand, MoD seamlessly amalgamates text-to-image generation techniques with state-of-the-art talking head algorithms, thereby streamlining the process of birthing articulate entities. However, this enterprising endeavor has not been without its challenges, as current models often yield anthropomorphic entities that elude pre-trained face landmark detectors, resulting in a lackluster performance in the realm of facial motion generation. To surmount this hurdle, a pixel-level guidance system has been incorporated during image generation, bestowing human-like facial landmarks upon the generated entities. This pixel-level intervention has proven to be a game-changer, significantly augmenting the face landmark detection rate and enabling automatic facial animation synchronized with the generated speech content.
The paper takes an in-depth look at the recent strides made in the field of large language models (LLMs) and their remarkable in-context learning capabilities, firmly situating them at the forefront of scholarly discourse. The researchers underscore the pressing need for a framework capable of churning out LLM-enhanced personas characterized by tailor-made personalities, voices, and visual attributes. In the pursuit of personality generation, they adroitly harness the in-context learning prowess of LLMs, fashioning a cornucopia of voice modules courtesy of text-to-speech (TTS) APIs. The Mixture of Voices (MoV) module then orchestrates the selection of tones, guided by user-provided textual inputs.
The aspect of visual appearance within speech-driven talking motions and expressions is addressed through the employment of cutting-edge talking head algorithms. Yet, the researchers have confronted a formidable challenge when utilizing images generated by diffusion models as input for these talking head models. Shockingly, a mere 30% of these images are discernible by state-of-the-art talking head models, highlighting a glaring distribution misalignment. To bridge this divide, the researchers proffer an ingenious zero-shot technique, wherein face landmarks are injected during the image generation phase.
The ChatAnything framework, as proposed, stands upon four sturdy pillars: the LLM-based control module, portrait initializer, mixture of text-to-speech modules, and motion generation module. Infused with diffusion models, voice modulation capabilities, and structural control, this framework emerges as a modular and highly adaptable system. To validate the efficacy of guided diffusion, the researchers meticulously curated a validation dataset featuring prompts from various categories. Here, a pre-trained face keypoint detector serves as the arbiter of face landmark detection rates, thereby illuminating the profound impact of their pioneering methodology.
Conclusion:
ChatAnything’s innovative framework revolutionizes LLM-based persona generation, offering customized personas with unique attributes. By overcoming challenges in image detection and alignment, this technology paves the way for seamless integration of generative models and talking head algorithms. It opens new avenues for digital character creation in various markets, from entertainment to customer service and beyond, offering limitless possibilities for personalization and engagement.