
TL;DR:
- D3GA introduces Drivable 3D Gaussian Avatars, a game-changing technology in 3D human body rendering.
- Unlike traditional methods, D3GA employs Gaussian splats for realistic representation, eliminating the need for complex preprocessing.
- It utilizes cages for volume transformations, allowing separate representations of the torso, face, and clothing, a departure from traditional approaches.
- D3GA’s condensed input based on human stance reduces the demand for dense signals and enhances its suitability for telepresence applications.
- The model outperforms the state-of-the-art, even when compared to methods with more data, offering promising results without ground truth geometry.
- D3GA has significant implications for industries like entertainment, gaming, and telepresence, ushering in new possibilities for hyper-realistic avatars.
Main AI News:
The world of AI research unveils a groundbreaking innovation – Drivable 3D Gaussian Avatars (D3GA). This cutting-edge technology marks a significant milestone in the quest for hyper-realistic human body rendering, transforming the way we perceive and interact with virtual characters. In this article, we delve into the revolutionary D3GA model, its unique features, and the trailblazing research behind it.
The Impressionist art movement, born in the 19th century, celebrated the beauty of short, broken brushstrokes that hinted at forms rather than defining them. Ironically, this artistic philosophy stood in stark contrast to the goal of contemporary AI research – creating photorealistic human subjects in photographs. Achieving this level of realism has been a formidable challenge, primarily due to the limitations of monocular techniques.
To generate drivable, photorealistic humans, researchers have traditionally relied on extensive multi-view data, accompanied by intricate pre-processing steps like precise 3D registrations. However, these processes are far from seamless and can be challenging to integrate into end-to-end workflows. Alternative approaches based on neuronal radiance fields (NeRFs) have faced their own hurdles, struggling with rendering clothing animations or real-time performance.
Enter the collaborative effort of researchers from Meta Reality Labs Research, Technical University of Darmstadt, and Max Planck Institute for Intelligent Systems, introducing the paradigm-shifting concept of 3D Gaussian avatars. Instead of traditional radiance fields, Gaussian splats serve as the modern brushstrokes, allowing avatars to mirror the anatomy and aesthetics of living, repositionable characters. Notably, this approach eliminates the need for complex hacks involving the sampling of camera rays.
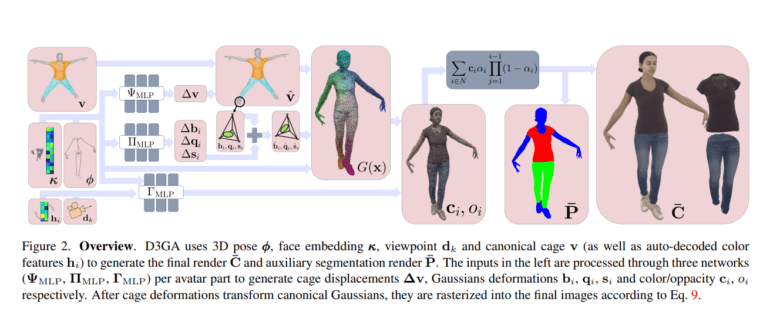
In contrast to the common practice of linear blend skinning (LBS) for transforming points from canonical space to observation space in drivable NeRFs, D3GA takes a different route. It employs cages, a well-established deformation model perfectly suited for volume transformations. Deforming these cages in canonical space generates deformation gradients that directly apply to the 3D Gaussian representation. This innovative approach enables the separate representation of the torso, face, and clothing using cages, marking a significant departure from traditional methods.
One of the mysteries that the research addresses is the cause of cage distortions. Previous state-of-the-art drivable avatars often demanded dense input signals like RGB-D images or complex multi-camera setups, making them less viable for low-bandwidth telepresence applications. The D3GA team has tackled this challenge by using a condensed input based on the human stance. This input includes quaternion representations of skeletal joint angles and 3D facial key points. By training person-specific models with nine high-quality multi-view sequences, D3GA can be driven with fresh poses from any subject, encompassing diverse body forms, motions, and clothing styles.
The results speak for themselves – D3GA outperforms the state-of-the-art, even when compared to methods utilizing more information, such as FFD meshes or images. Remarkably, this technique doesn’t require ground truth geometry, significantly reducing processing time for data while maintaining promising results in geometry and appearance modeling for dynamic sequences.
Conclusion:
Drivable 3D Gaussian Avatars represent a paradigm shift in the realm of AI-driven human body rendering. With their ability to blend artistry and technology, they offer a glimpse into a future where realism knows no bounds. This innovation promises to reshape industries across entertainment, gaming, telepresence, and beyond, opening doors to new realms of possibility in the world of digital avatars.