
TL;DR:
- GAIA, a collaborative project by FAIR Meta, HuggingFace, AutoGPT, and GenAI Meta, addresses the challenge of assessing AI assistants’ real-world capabilities.
- It focuses on tasks that require advanced reasoning and multi-modality skills, setting a new benchmark for AI evaluation.
- GAIA’s methodology employs human-crafted questions and a quasi-exact match approach to ensure accurate evaluation.
- Results show a substantial performance gap between humans and GPT-4, highlighting the need for improvements in General AI Assistants.
- Augmenting LLMs with tool APIs or web access presents opportunities for collaborative human-AI models and advancements in AI systems.
Main AI News:
Cutting-edge research teams at FAIR Meta, HuggingFace, AutoGPT, and GenAI Meta have joined forces to tackle a pressing challenge in the field of artificial intelligence – the assessment of general AI assistants’ capabilities when confronted with real-world inquiries that demand advanced skills in reasoning and multi-modality handling. These inquiries often prove to be a formidable hurdle for even the most advanced AIs that endeavor to mimic human-like responses. Enter GAIA, a groundbreaking development poised to redefine the landscape of Artificial General Intelligence (AGI) by striving for human-level resilience.
With an exclusive focus on real-world questions that necessitate adept reasoning and multi-modality skills, GAIA breaks away from the current trends in AI benchmarking. It deliberately chooses tasks that are as demanding for humans as they are for advanced AIs. Unlike closed-system evaluations, GAIA mirrors genuine AI assistant usage scenarios, setting itself apart as a formidable contender. Within GAIA’s repertoire are meticulously curated questions, chosen to uphold the highest standards of quality and to demonstrate human superiority over GPT-4, supplemented by its own range of plugins. Its mission is to become the guiding light for question design, ensuring intricate multi-step problem solving while safeguarding against data contamination.
As Large Language Models (LLMs) continue to surpass existing benchmarks, evaluating their capabilities becomes an increasingly complex endeavor. Researchers contend that the difficulty levels posed by these models do not necessarily challenge human intellect. In response to this dilemma, the research community has introduced GAIA – a general AI assistant tailored to tackle real-world questions and bypass the evaluation pitfalls inherent in LLMs. By employing human-crafted questions that mirror the practicality of AI assistant usage, GAIA takes the reins in the quest for open-ended natural language generation (NLP). Its aspiration is to redefine the standards for evaluating AI systems and to propel the next generation of AI to new heights.
One of the key innovations introduced by GAIA is a novel research methodology that leverages a benchmark specifically created for evaluating general AI assistants. This benchmark comprises genuine real-world questions that prioritize reasoning abilities and practical skills. These questions have been meticulously designed by humans to ensure the integrity of the evaluation process, preventing any contamination of data and facilitating an efficient and fact-based assessment. The evaluation procedure employs a quasi-exact match approach, aligning model-generated responses with ground truth through a carefully constructed system prompt. To kickstart this initiative, a developer set and a corpus of 300 questions have been released, paving the way for the establishment of a comprehensive leaderboard. The methodology behind GAIA’s benchmark aims to scrutinize the landscape of open-ended natural language generation within NLP and provide invaluable insights to drive advancements in the next generation of AI systems.
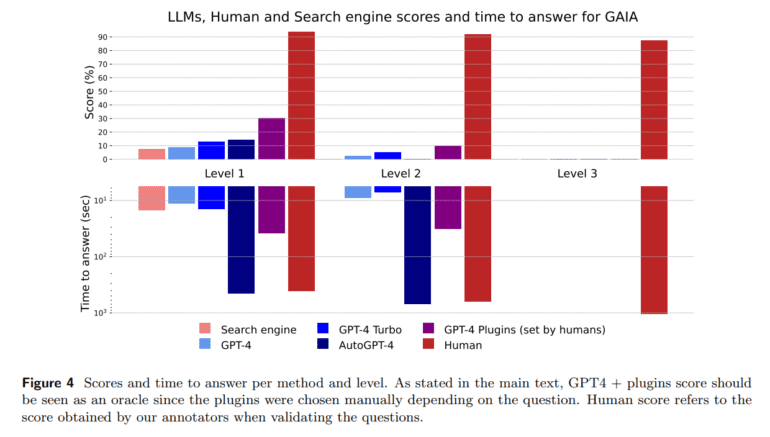
The results unveiled by GAIA’s benchmark underscore a significant performance gap between human intelligence and GPT-4 when addressing real-world queries. While humans achieved an impressive success rate of 92%, GPT-4 lagged behind with a mere 15%. Nonetheless, GAIA’s evaluation has shed light on a promising avenue for improvement – augmenting LLMs with tool APIs or web access. This revelation opens the door to collaborative human-AI models and potential breakthroughs in next-generation AI systems. In summary, the benchmark not only offers a definitive ranking of AI assistants but also emphasizes the pressing need for ongoing enhancements in the realm of General AI Assistants.
Conclusion:
GAIA’s introduction signifies a significant step forward in evaluating AI assistants’ practicality in handling real-world questions. This benchmarking approach underscores the potential for improvement in AI performance and opens doors for collaborative models, suggesting a promising trajectory for the AI market’s evolution.