
TL;DR:
- Korea University introduced HierSpeech++, an advanced AI-driven speech synthesizer.
- HierSpeech++ achieves high-fidelity, natural, and human-like speech without text-speech paired datasets.
- It outperforms LLM-based and diffusion-based models, addressing speed and robustness issues.
- Hierarchical framework and self-supervised representations enhance speech generation.
- Comprehensive assessment using various metrics proves its superiority.
- HierSpeech++ offers superior naturalness and versatility with style transfer capabilities.
Main AI News:
In a groundbreaking development, researchers at Korea University have unveiled HierSpeech++, a cutting-edge AI approach that redefines high-fidelity and efficient text-to-speech and voice conversion. This innovation represents a significant leap in the realm of synthetic speech, aiming to deliver speech that is not only robust but also exhibits expressiveness, naturalness, and a striking human-like quality. Remarkably, this achievement has been realized without the crutch of a text-speech paired dataset, addressing the limitations of existing models while ushering in an era of superior style adaptation.
The Challenge: Overcoming Limitations of Zero-Shot Speech Synthesis
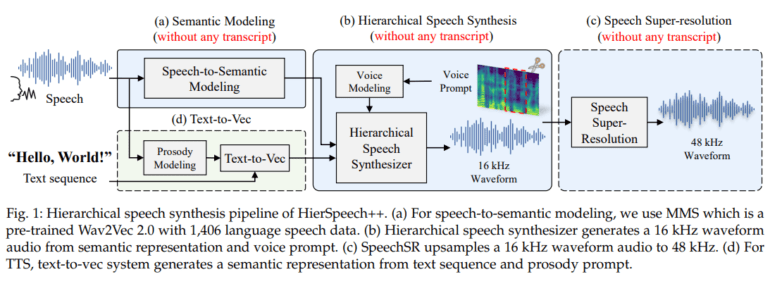
Traditionally, zero-shot speech synthesis relying on Large Language Models (LLM) has faced inherent limitations. However, HierSpeech++ emerges as the solution to these challenges, enhancing robustness, expressiveness, and addressing issues associated with slow inference speeds. Leveraging a text-to-vec framework that generates self-supervised speech and F0 representations based on text and prosody prompts, HierSpeech++ has not only surpassed LLM-based models but also outperformed diffusion-based models in terms of speed, robustness, and quality. This remarkable feat firmly establishes HierSpeech++ as a formidable zero-shot speech synthesizer.
The Hierarchical Framework: Revolutionizing Speech Generation
HierSpeech++ adopts a hierarchical framework that eliminates the need for prior training. It harnesses the power of a text-to-vec framework to create self-supervised address and F0 representations, driven by text and prosody prompts. The speech itself is generated through a hierarchical variational autoencoder, combined with a generated vector, F0, and voice prompt. Additionally, an efficient speech super-resolution framework is integrated into the process. To comprehensively assess its performance, HierSpeech++ undergoes rigorous testing with various pre-trained models, evaluated through objective and subjective metrics. These include log-scale Mel error distance, perceptual evaluation of speech quality, pitch, periodicity, voice/unvoice F1 score, naturalness, mean opinion score, and voice similarity MOS.
Unparalleled Naturalness and Versatility
HierSpeech++ emerges as a frontrunner in achieving superior naturalness in synthetic speech within zero-shot scenarios, boasting enhancements in robustness, expressiveness, and speaker similarity. The evaluation results, particularly in terms of naturalness mean opinion score and voice similarity MOS, demonstrate that HierSpeech++ surpasses ground-truth speech. Furthermore, the incorporation of a speech super-resolution framework from 16 kHz to 48 kHz enhances the naturalness of the output. Notably, the hierarchical variational autoencoder employed in HierSpeech++ outperforms LLM-based and diffusion-based models, solidifying its status as a robust zero-shot speech synthesizer.
Unlocking the Potential: Versatile Prosody and Voice Style Transfer
HierSpeech++ introduces a revolutionary hierarchical synthesis framework that allows for versatile prosody and voice style transfer. This innovation empowers synthesized speech with unprecedented flexibility, opening up new horizons for expressive communication.
Conclusion:
HierSpeech++ represents a major breakthrough in AI-powered speech synthesis, offering high-fidelity, natural, and versatile speech without the need for paired datasets. Its performance superiority over existing models and the ability to bridge the gap in speech synthesis are promising developments for the market, with potential applications in various industries such as customer service, voice assistants, and entertainment. This innovation from Korea University sets a new standard for speech synthesis technology.