
TL;DR:
- SAM and SCA bridge the gap in generating regional captions for images.
- SCA adds a lightweight feature mixer to SAM, aligning visual and linguistic elements.
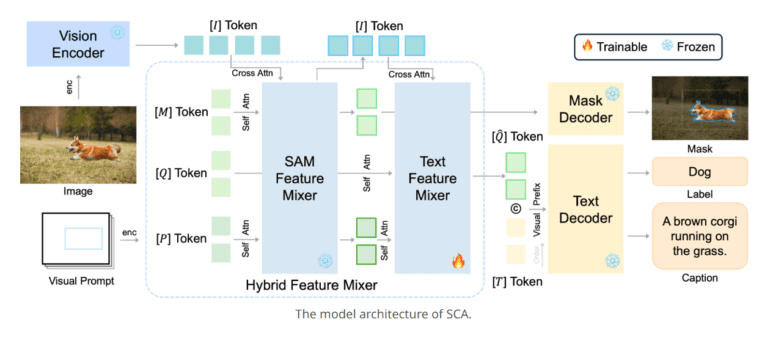
- SCA’s architecture consists of an image encoder, feature mixer, and decoder heads.
- SCA achieves efficiency with a small parameter count, expediting training.
- Weak supervision pre-training overcomes scarcity in regional caption data.
- Extensive experiments confirm SCA’s adaptability and strong performance in Referring Expression Generation (REG) tasks.
Main AI News:
In the ever-evolving landscape of computer vision and natural language processing, the challenge of generating regional captions for entities within images has been a persistent puzzle. This complexity is exacerbated by the absence of semantic labels in training data, pushing researchers to seek efficient solutions that enable models to comprehend and articulate the diverse elements within images.
Enter the Segment Anything Model (SAM), a class-agnostic segmentation model renowned for its remarkable entity segmentation capabilities. However, SAM’s potential applications have been somewhat constrained by its inability to generate regional captions. In response to this limitation, a collaborative research effort between Microsoft and Tsinghua University has introduced a groundbreaking solution: SCA, short for Segment and Caption Anything. SCA stands as a strategic augmentation of SAM, meticulously engineered to bestow upon it the capacity for efficient regional caption generation.
Much like the building blocks of a solid foundation, SAM serves as the cornerstone for segmentation, while SCA adds a pivotal layer to this foundation. This addition takes the form of a lightweight query-based feature mixer, setting it apart from traditional mixers. This component effectively bridges SAM with causal language models, harmonizing region-specific features with the linguistic embedding space. This alignment is a critical catalyst for subsequent caption generation, forging a powerful synergy between SAM’s visual comprehension and the linguistic prowess of language models.
The architectural blueprint of SCA is meticulously composed of three primary components: an image encoder, a feature mixer, and decoder heads dedicated to masks or text. Among these, the feature mixer takes center stage as the linchpin of the model. It operates as the connective tissue between SAM and language models, optimizing the alignment of region-specific features with language embeddings.
SCA’s strength lies in its efficiency, a feat achieved with a relatively small number of trainable parameters, typically in the tens of millions. This strategic optimization focuses predominantly on enhancing the feature mixer while preserving the integrity of SAM tokens. This streamlined approach expedites the training process, making it more scalable and resource-efficient.
To tackle the challenge of limited regional caption data, the research team adopts a pre-training strategy with weak supervision. In this innovative approach, the model is pre-trained on object detection and segmentation tasks, leveraging datasets that provide category names rather than full-sentence descriptions. This unique form of weak supervision pre-training serves as a practical solution, enabling the transfer of general visual knowledge beyond the constraints of scarce regional captioning data.
Extensive experimentation has been conducted to validate the effectiveness of SCA. Comparative analyses against baselines, evaluations of various Vision Large Language Models (VLLMs), and comprehensive testing of diverse image encoders have all been part of the rigorous assessment. The results speak volumes, as the model demonstrates exceptional zero-shot performance on Referring Expression Generation (REG) tasks, underscoring its adaptability and robust generalization capabilities.
Conclusion:
The introduction of SCA as an augmentation to the SAM model represents a significant leap forward in the field of computer vision and natural language processing. This innovation unlocks new possibilities for image understanding and communication, with implications for a wide range of industries such as e-commerce, healthcare, and autonomous vehicles. Businesses can harness the power of SCA to enhance their image-related applications, improve user experiences, and gain a competitive edge in the market by providing more contextually relevant and descriptive content.