
TL;DR:
- Research presented at RSNA 2023 discusses safeguarding AI diagnostic algorithms against adversarial attacks.
- University of Pittsburgh’s novel strategies bolster AI models’ defense and improve patient safety.
- Adversarial attacks on medical AI image classifiers pose serious risks, from misdiagnoses to fraud.
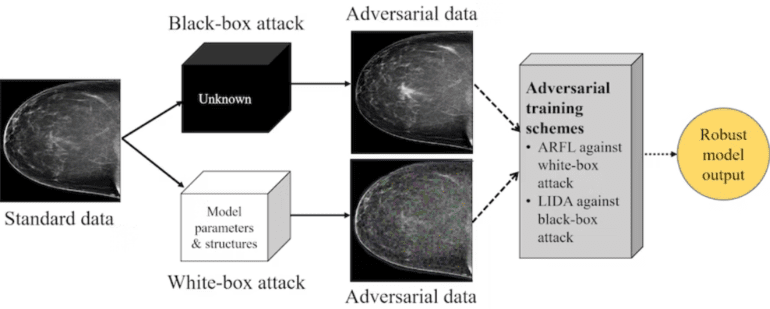
- Two defense methods, ARFL and LIDA, protect against white-box and black-box attacks.
- ARFL enhances model performance and discriminative feature identification.
- Ensuring the security and safety of medical AI models is imperative.
- Broad deployment of medical AI models increases the risk of adversarial attacks.
Main AI News:
In the rapidly evolving landscape of artificial intelligence (AI) in healthcare, safeguarding diagnostic algorithms against adversarial attacks has become a paramount concern. Recent research unveiled at RSNA 2023 in Chicago demonstrates that innovative training methodologies can fortify AI models, thereby mitigating the risk of medical errors resulting from adversarial interference.
At the heart of this endeavor lies an exploration of security techniques developed by the University of Pittsburgh. These strategies not only hold the promise of enhancing patient safety but also thwarting potential fraud within the healthcare ecosystem. The foundation for this work rests upon earlier investigations into the feasibility of adversarial attacks, both in the black-box and white-box paradigms, wherein data generated by generative adversarial networks (GANs) is artfully inserted into medical images to deceive diagnostic AI models.
Adversarial attacks on AI-based medical image classifiers pose a multifaceted challenge, as they can deceive not only the diagnostic models themselves but also the human radiologists interpreting the images. These attacks range from compromising diagnostic accuracy to perpetrating insurance fraud or exerting undue influence over the outcomes of clinical trials.
Degan Hao, the lead author of the RSNA presentation, and Shandong Wu, PhD, the corresponding senior author, emphasized the specific vulnerabilities that medical machine-learning diagnostic models exhibit. Their research revealed that merely introducing adversarial noise into standard image data can lead to erroneous diagnoses by machine-learning models.
Security Strategies for Breast Cancer Diagnosis
To shield AI models against adversarial attacks, the University of Pittsburgh research team devised two innovative defense strategies within the domain of breast cancer diagnosis. Breast cancer, with its abundance of available data, provided a robust context for this study, given the proliferation of medical imaging-based AI diagnostic models in this field.
Utilizing a dataset comprising 4,346 mammogram images, Hao, Wu, and their colleagues employed a technique called adversarial training to defend against two categories of adversarial attacks manifested in the images:
1. White-box attack: In this scenario, attackers possess knowledge of AI model parameters. Adversarial data generated through projected gradient descent were employed to introduce perturbations into mammogram images. To counter such attacks, the researchers devised a “regularization algorithm” facilitating adversarially robust feature learning (ARFL). ARFL involves training models with a blend of pristine data and adversarial samples.
2. Black-box attack: Here, attackers lack access to AI model parameters. Adversarial data, crafted using GANs, were strategically embedded with positive- and negative-looking adversarial image features. The researchers confronted the challenge of “label leakage” in routine adversarial training with GAN-generated samples, a phenomenon that inaccurately inflates model performance. To counter this, they introduced a technique called label independent data augmentation (LIDA), allowing the model to focus on authentic classification features.
Vulnerabilities and Enhanced Performance
The researchers discovered that conventional training methods were vulnerable to black-box attacks. In contrast, LIDA successfully addressed the label leakage issue and preserved model performance in the presence of adversarial data, without sacrificing its performance on standard data.
Moreover, the ARFL method not only restored high performance in the face of white-box attacks but also maintained a performance level close to that achieved through standard training on standard data. The feature saliency maps analysis revealed that ARFL models identified a greater number of sharply contrasted regions, suggesting an improvement in learning discriminative features for diagnostic purposes.
The Imperative of Security and Safety
According to Wu, the security and safety of medical AI models loom as critical concerns, especially as they begin to find their footing within clinical environments. These models must not only uphold their accuracy but also demonstrate resilience against potential cybersecurity threats, including adversarial attacks.
Wu further explained, “For black-box attacks, hackers could simply use publicly available data to train GAN models to perform attacks without access to the model parameters, making it a relatively ‘easier’ setting to perform attacks. Currently, the risk of adversarial attacks is relatively low, partly due to a lack of comprehensive understanding of AI/ML model vulnerabilities to adversarial samples. However, this landscape could shift with broader deployment and utilization of such models in medical infrastructure and services.”
While this study at the University of Pittsburgh focused on one institution’s data, the researchers plan to extend their investigations of ARFL and LIDA to other medical imaging modalities, underscoring the ongoing commitment to fortifying AI-based healthcare technologies against adversarial threats.
Conclusion:
The development of robust defense strategies against adversarial attacks in medical AI diagnosis models signifies a significant advancement in healthcare technology. As these models gain traction in clinical settings, ensuring their security and resilience to cyber threats becomes imperative. This innovation enhances patient safety, reduces the risk of fraud, and reinforces the market’s confidence in the capabilities of AI-powered healthcare solutions.