
TL;DR:
- Google researchers unveil ReAct-style LLM agent for complex question-answering.
- LLM agents handle intricate queries using external tools and APIs.
- Challenges arise due to non-differentiable interactions with external knowledge.
- A ReST-like technique enhances agent performance and resilience.
- The agent achieves continuous self-improvement over time.
- A compact model outperforms larger models in challenging question-answering tasks.
Main AI News:
In the era of Large Language Models (LLMs), the realm of Artificial Intelligence (AI) has been nothing short of revolutionary. These LLMs have dazzled us with their remarkable prowess in tasks like content generation and question-answering. However, when it comes to addressing intricate, open-ended queries that demand interaction with external tools or APIs, there remain certain challenges that require innovative solutions.
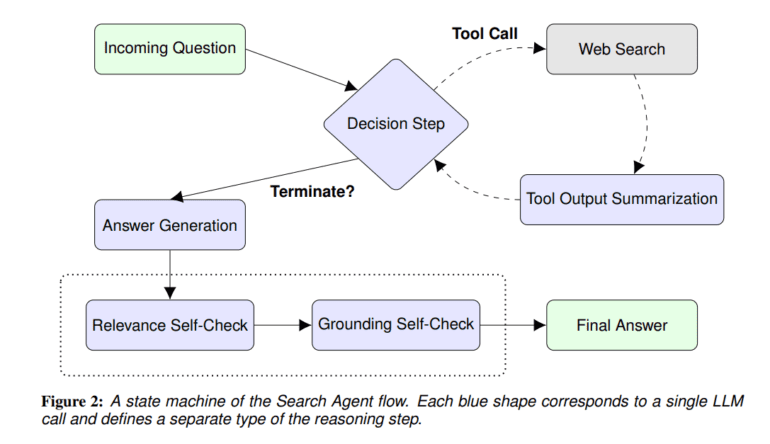
While outcome-based systems excel in handling simpler tasks with readily available feedback, tackling complex problems often necessitates a process supervision approach. This approach involves breaking down tasks into human-understandable workflows, which we refer to as LLM agents. These agents harness external tools and APIs to execute multi-step processes and achieve specific objectives. A prime example of this is the task of answering complex questions by collecting data and constructing comprehensive responses using a search API.
Existing models, although proficient in addressing complex natural language queries that require multi-step reasoning and integration of external information, face obstacles due to the non-differentiable nature of interactions with external knowledge. Furthermore, training these models end-to-end to rectify these errors is far from straightforward.
To confront these challenges head-on, a team of Google researchers has proposed the development of a ReAct-style LLM agent. This agent possesses the unique ability to think and act in response to external information, effectively managing multi-step procedures to address intricate queries.
The team has introduced a ReST-like technique to further enhance the agent’s performance and resilience in the face of failure scenarios. This technique employs a growing-batch reinforcement learning strategy coupled with AI feedback, enabling iterative training based on previous trajectories. The ultimate goal is to empower the agent with continuous self-improvement and refinement over time.
It is worth noting that, astonishingly, the team achieved a finely-tuned compact model after just two algorithm runs, starting from a larger model. Despite having significantly fewer parameters, this smaller model demonstrated comparable performance in tackling challenging compositional question-answering benchmarks. The future of AI is indeed evolving, with Google’s ReAct-style LLM agent paving the way for more sophisticated and capable systems in the world of complex question-answering.
Conclusion:
Google’s ReAct-Style LLM Agent represents a significant leap in the field of AI, particularly for complex question-answering. By addressing the challenges of interacting with external knowledge and continuously improving its performance, this innovation opens doors to more capable and efficient AI systems, promising exciting possibilities for the market’s future.