
TL;DR:
- RWKV model combines RNNs and Transformers, offering advantages of both.
- Researchers from multiple institutions collaborated on RWKV development.
- RWKV enhances efficiency with linear attention and custom initializations.
- It performs competitively in natural language processing tasks.
- Limitations include the potential loss of fine details over time and a focus on engineering expediency.
Main AI News:
Advancements in the realm of deep learning have catalyzed a transformative wave across scientific and industrial domains within artificial intelligence. In this dynamic landscape, applications spanning natural language processing, conversational AI, time series analysis, and the manipulation of intricate sequential data formats like images and graphs have taken center stage. Within this milieu, two prominent methodologies, Recurrent Neural Networks (RNNs) and Transformers, stand out, each offering its unique set of advantages and challenges.
RNNs, with their lower memory demands, shine when dealing with lengthy sequences. However, their Achilles’ heel lies in their inability to scale due to issues such as the vanishing gradient problem and non-parallelizability in the time dimension.
Enter Transformers, the heralds of parallelized training and versatile handling of short- and long-term dependencies. Models like GPT-3, ChatGPT LLaMA, and Chinchilla have demonstrated the prowess of Transformers in natural language processing. Nonetheless, Transformers are not without their flaws. Their self-attention mechanism, with its quadratic complexity, exacts a heavy computational and memory toll, rendering it less suited for resource-constrained tasks and extended sequences.
A consortium of innovative researchers has embarked on a mission to bridge these chasms. Their brainchild, the Acceptance Weighted Key Value (RWKV) model, amalgamates the best attributes of RNNs and Transformers while sidestepping their critical shortcomings. Inheriting the expressive qualities of Transformers, including parallelized training and robust scalability, RWKV circumvents memory bottlenecks and quadratic scaling through the magic of efficient linear scaling.
Conducted by a diverse group of institutions, including Generative AI Commons, Eleuther AI, University of Barcelona, Charm Therapeutics, Ohio State University, University of California, Santa Barbara, Zendesk, Booz Allen Hamilton, Tsinghua University, Peking University, Storyteller.io, Crisis, New York University, National University of Singapore, Wroclaw University of Science and Technology, Databaker Technology, Purdue University, Criteo AI Lab, Epita, Nextremer, Yale University, RuoxinTech, University of Oslo, University of Science and Technology of China, Kuaishou Technology, University of British Columbia, University of California, Santa Cruz, and University of Electronic Science and Technology of China, this study propels RWKV into the limelight.
RWKV accomplishes this feat by overhauling the attention mechanism, replacing the inefficient dot-product token interaction with the nimble channel-directed attention, utilizing a variant of linear attention that is devoid of approximations. This novel approach substantially reduces computational and memory complexity.
The transformation continues by reshaping recurrence and sequential inductive biases, facilitating efficient training parallelization, and introducing a linear-cost scalar formulation to replace the quadratic QK attention. Custom initializations further enhance training dynamics, ensuring RWKV can surmount the limitations that beset existing architectures while adeptly capturing locality and long-range dependencies.
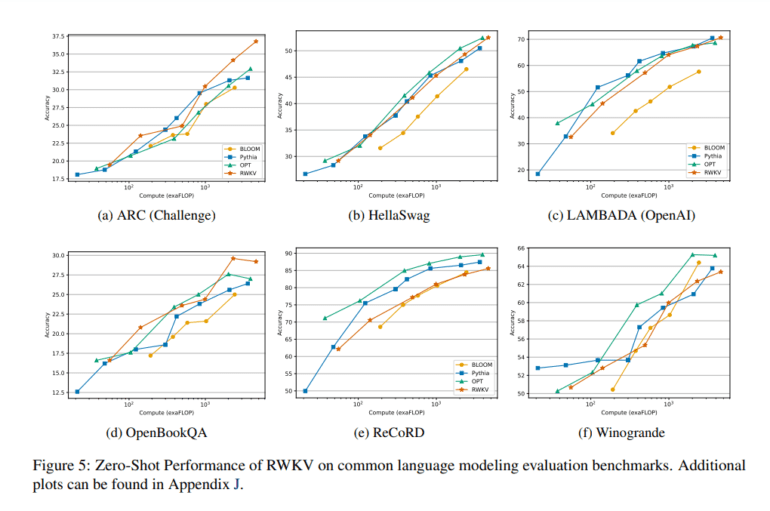
Comparative evaluations against state-of-the-art models reveal that RWKV performs on par while offering significant cost savings across a spectrum of natural language processing (NLP) tasks. Additional assessments for interpretability, scale, and expressivity underscore the model’s prowess, unveiling behavioral congruities with other Large Language Models (LLMs). RWKV forges a new path toward efficiently and scalably modeling intricate sequential data relationships, amid a landscape crowded with Transformer alternatives.
However, the researchers acknowledge certain constraints inherent to their creation. While RWKV’s linear attention yields remarkable efficiency gains, it may hinder the model’s ability to retain fine-grained details over extended periods. Unlike conventional Transformers, which uphold all information through quadratic attention, RWKV relies on a single vector representation across multiple time steps. Additionally, RWKV prioritizes engineering expediency over conventional Transformer models, as its linear attention mechanism restricts the volume of prompt-related data transmitted to subsequent model iterations. Hence, well-crafted cues become pivotal for the model’s performance in various tasks.
Conclusion:
The RWKV model represents a significant breakthrough in AI architecture, effectively marrying the strengths of RNNs and Transformers while mitigating their weaknesses. Its efficient approach and competitive performance in natural language processing tasks make it a promising contender in the market. However, potential limitations in retaining fine details and a bias towards engineering expediency should be considered in its application.