
TL;DR:
- Unsupervised machine learning methods may prioritize prominent features over latent knowledge in Large Language Models (LLMs).
- Google DeepMind and Google Research address these challenges, focusing on LLM activation data and contrast pairs to refine knowledge discovery.
- A hypothesis suggests that LLMs encode knowledge as credentials adhering to probability laws.
- The study introduces “contrast-consistent search” (CCS) as an unsupervised method but questions its accuracy.
- Two unsupervised learning methods (CRC-TPC and k-means) are evaluated for knowledge discovery in LLMs.
- Logistic regression and a random baseline serve as benchmark methods.
- Distinguishing model knowledge from simulated characters remains a persistent challenge in unsupervised approaches.
Main AI News:
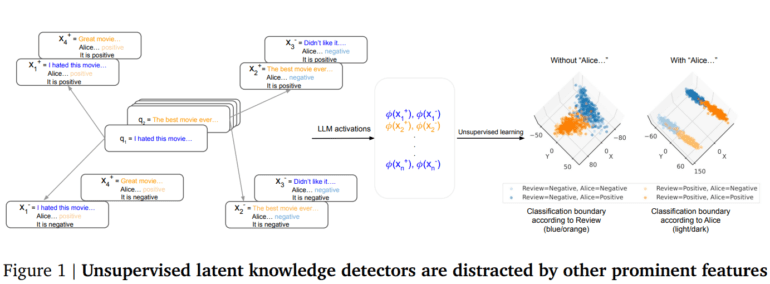
Uncovering hidden insights within Large Language Models (LLMs) has become a focal point in the field of artificial intelligence. Recent research from Google DeepMind raises questions about the efficacy of unsupervised machine learning methods when it comes to extracting knowledge from these colossal language models.
The prevailing issue with unsupervised methods is their propensity to emphasize prominent features while overlooking the subtler nuances of knowledge. These arbitrary components often conform to a consistent structure, making it challenging to differentiate between genuine knowledge and superficial patterns. To address this, there is a pressing need for improved evaluation criteria to ascertain the true depth of knowledge extracted from LLMs.
In response to this challenge, researchers from Google DeepMind and Google Research have embarked on a journey to refine unsupervised knowledge discovery techniques. Their focus lies on methods employing probes trained on LLM activation data, specifically generated from contrast pairs of texts ending with “Yes” and “No.” To ensure the accuracy of their findings, a normalization step is introduced to mitigate the influence of prominent features associated with these endings.
One intriguing hypothesis emerges from this research: if knowledge indeed resides within LLMs, it is likely encoded as credentials adhering to probability laws. This insight opens up new avenues for understanding how LLMs store and process information.
The study also introduces the concept of “contrast-consistent search” (CCS) as an unsupervised method for knowledge extraction. However, it questions the method’s accuracy in eliciting latent knowledge, suggesting that its applicability may extend primarily to arbitrary binary features. This observation challenges the specificity of CCS for knowledge elicitation and calls for a more comprehensive approach to unearth the true depths of LLM knowledge.
In the pursuit of knowledge discovery, the research evaluates two unsupervised learning methods:
- CRC-TPC, a PCA-based approach that leverages contrastive activations and top principal components.
- A k-means method that employs two clusters with truth-direction disambiguation.
To establish a benchmark for comparison, logistic regression, utilizing labeled data, serves as the ceiling method, while a random baseline, utilizing a probe with randomly initialized parameters, acts as the floor method. These methods are rigorously assessed for their effectiveness in uncovering latent knowledge within LLMs, offering a comprehensive evaluation framework for future studies.
Conclusion:
The study underscores the limitations of current unsupervised methods applied to LLM activations. While LLMs exhibit proficiency in various tasks, the difficulty lies in accessing their latent knowledge, which often results in potentially inaccurate outputs. As we navigate the uncharted territory of LLM knowledge discovery, it is imperative to address the persistent challenges of distinguishing model knowledge from that of simulated characters in forthcoming unsupervised approaches. Only by doing so can we unlock the true potential of these remarkable language models.