
TL;DR:
- Diffusion models in video generation have faced challenges in temporal consistency.
- Researchers at S-Lab and Nanyang Technological University introduced FreeInit.
- FreeInit refines initial noise during inference, improving temporal consistency.
- The study focuses on diffusion-based video models and their training-inference gap.
- FreeInit enhances temporal consistency and inference quality in text-to-video models.
- Quantitative assessments on datasets confirm FreeInit’s superiority.
Main AI News:
In the ever-evolving landscape of video generation, diffusion models have undeniably showcased remarkable advancements. Yet, a persistent challenge has cast a shadow over their brilliance – the issue of unsatisfactory temporal consistency and unnatural dynamics in inference results. This critical concern led to a deep dive into the intricacies of noise initialization in video diffusion models, ultimately unveiling a pivotal training-inference gap.
Addressing the Challenges in Diffusion-Based Video Generation
The study, conducted by the esteemed researchers at S-Lab and Nanyang Technological University, is a testament to the relentless pursuit of innovation. It sheds light on the challenges in diffusion-based video generation, with a laser focus on the training-inference gap in noise initialization that has been the Achilles’ heel of this technology. What the study reveals is nothing short of groundbreaking – the existence of intrinsic differences in spatial-temporal frequency distribution between the training and inference phases.
Introducing FreeInit: A Game-Changing Inference Sampling Strategy
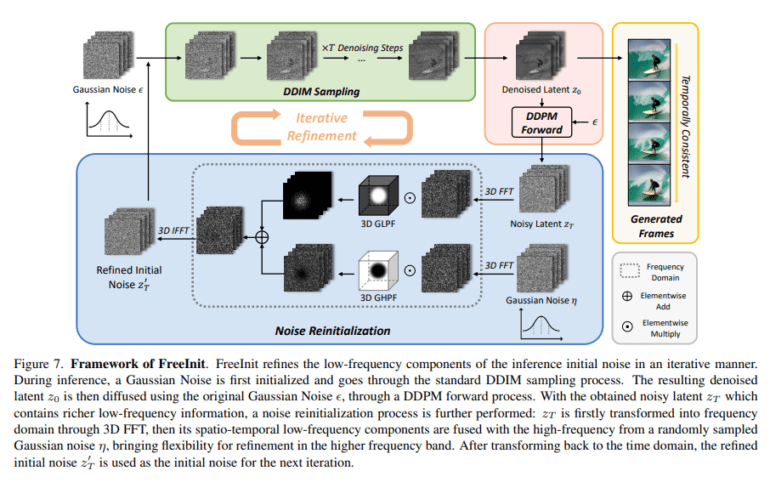
In response to this revelation, the research team introduced FreeInit, a concise yet potent inference sampling strategy. FreeInit is a method that iteratively refines the low-frequency components of initial noise during inference, effectively bridging the troublesome initialization gap. This breakthrough innovation promises to revolutionize the landscape of diffusion-based video generation.
Unlocking the Potential of Diffusion-Based Models
The study explores three distinct categories of video generation models – GAN-based, transformer-based, and diffusion-based. However, it is the diffusion-based models that steal the spotlight. Names like VideoCrafter, AnimateDiff, and ModelScope have made waves in text-to-image and text-to-video generation. Yet, lurking beneath their success was the implicit training-inference gap in noise initialization, silently impacting the quality of inference results.
A Leap Forward in Text-to-Video Generation
Diffusion models, which have previously excelled in text-to-image generation, were extended to the realm of text-to-video with the aid of pretrained image models and temporal layers. Despite this progress, the nagging training-inference gap in noise initialization continued to hinder performance. Enter FreeInit – the silver bullet that addresses this gap without the need for extra training. FreeInit works its magic by enhancing temporal consistency and refining the visual appearance of generated frames. When put to the test against public text-to-video models, FreeInit emerges as the hero, significantly elevating the quality of the generation.
Quantifying the Advancements
To quantify the significance of FreeInit’s contributions, the study employs a range of evaluation metrics. Frame-wise similarity and the DINO metric, utilizing ViT-S16 DINO, are key tools used to assess temporal consistency and visual quality. The results are nothing short of spectacular – FreeInit leaves its mark with an exceptional improvement in temporal consistency, with gains ranging from 2.92 to 8.62. The quantitative assessments conducted on UCF-101 and MSR-VTT datasets further solidify FreeInit’s superiority, as indicated by performance metrics such as the DINO score. It surpasses models that either lack noise reinitialization or rely on different frequency filters.

Source: Marktechpost Media Inc.
Conclusion:
The introduction of FreeInit marks a significant advancement in the field of diffusion-based video generation, addressing the persistent challenge of temporal consistency. This breakthrough innovation has the potential to revolutionize the market by improving the quality of generated videos, making them more natural and appealing to users. As businesses explore the possibilities of AI-generated video content, FreeInit provides a valuable tool to enhance the overall user experience and drive market growth in this emerging industry.