
TL;DR:
- Cohere AI researchers investigate the impact of post-training quantization (PTQ) on large language models (LLMs).
- They analyze optimization choices like weight decay, dropout, gradient clipping, and half-precision training.
- Cohere AI challenges the belief that model scale is the sole determinant of quantization performance.
- Their findings show that higher weight decay during pre-training enhances quantization performance.
- Dropout and gradient clipping are crucial for ensuring quantization stability.
- The choice of half-precision training data type, specifically bfloat16, is highlighted as more quantization-friendly.
- Experiments are conducted on models ranging from 410 million to 52 billion parameters.
- Early checkpoints can reliably predict fully trained model performance.
Main AI News:
The era of artificial intelligence has ushered in an unprecedented era of large language models (LLMs) that have revolutionized natural language processing. However, the deployment of these colossal models comes with its own set of challenges, with post-training quantization (PTQ) emerging as a pivotal factor influencing their performance. Quantization, the process of reducing model weights and activations to lower bit precision, is essential for enabling the deployment of models on resource-constrained devices. The conundrum lies in deciphering whether sensitivity to quantization is an inherent characteristic at scale or a consequence of the optimization decisions made during pre-training.
In their relentless pursuit of unraveling the intricacies of PTQ sensitivity, Cohere AI’s team of researchers has meticulously designed and executed a series of experiments. Their objective is to delve into the optimization choices, such as weight decay, dropout, gradient clipping, and half-precision training, and gain insights into their impact on pre-training performance and subsequent quantization robustness. This approach challenges the prevailing belief that specific characteristics are solely dictated by the scale of the model, asserting that the optimization decisions made during pre-training play a significant role in quantization performance. Their nuanced methodology aims to provide a comprehensive understanding of the interplay between model architecture, optimization strategies, and quantization outcomes.
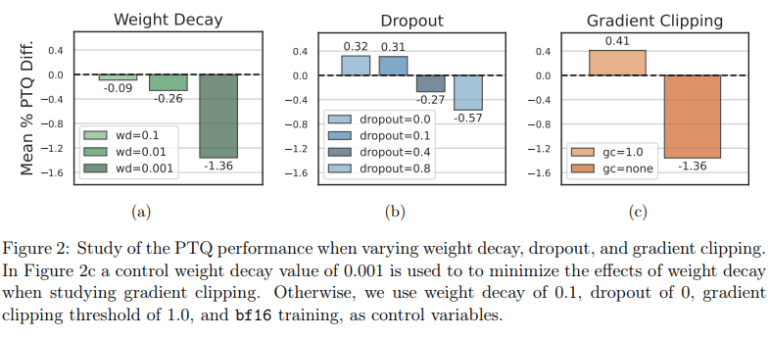
The researchers embark on a journey to dissect the intricacies of their method by conducting a thorough analysis of various optimization choices. Weight decay, a widely adopted technique to combat overfitting, undergoes scrutiny, revealing that higher levels of weight decay during pre-training result in enhanced post-training quantization performance. The study systematically investigates the effects of dropout and gradient clipping, showcasing that these regularization techniques are pivotal in ensuring quantization stability. Another pivotal aspect explored is the selection of the half-precision training data type, with a comparison between models trained with float16 (fp16) and bfloat16 (bf16). The findings shed light on the fact that emergent features are less pronounced when training with bf16, indicating its potential as a more quantization-friendly data type.
To validate their groundbreaking observations, the researchers meticulously conduct experiments on models of varying sizes, ranging from 410 million to a staggering 52 billion parameters. The controlled experiments on smaller models lay the foundation, and the invaluable insights derived from them are rigorously validated on larger models. The researchers acknowledge the computational challenges of training these mammoth models and stress the importance of relying on early checkpoints to infer the behavior of fully trained models. Despite the formidable challenges, the findings offer a glimmer of hope by suggesting that performance at early checkpoints can serve as a reliable predictor of the ultimate performance of these models in their fully trained state.
Conclusion:
Cohere AI’s research illuminates the intricate relationship between optimization choices and quantization challenges in large language models. Their findings provide valuable insights for businesses and industries relying on AI technologies, emphasizing the need for thoughtful optimization strategies to enhance model performance and reduce resource constraints, ultimately paving the way for more efficient AI deployment in the market.