
TL;DR:
- Single-view 3D reconstruction is a prominent challenge in computer vision.
- Oxford researchers introduced the “Splatter image” technique for 3D object reconstruction.
- The method leverages Gaussian Splatting and neural networks for rapid, high-quality results.
- It encodes a 360-degree view within a 2D image and efficiently removes inactive Gaussians.
- Splatter Image is remarkably efficient, requiring only a single GPU for training.
- It can handle multiple views as input, providing a unified representation.
- This technique excels in rapid inference, achieving real-time rendering with top-tier image quality.
Main AI News:
Single-view 3D reconstruction has long been a challenging frontier in computer vision, offering immense potential for diverse applications such as robotics, augmented reality, medical imaging, and cultural heritage preservation. The task involves deducing the three-dimensional structure and appearance of an object or scene from a single 2D image, spurring relentless innovation in the field of computer vision.
Despite remarkable progress, formidable obstacles persist. Challenges include precise depth estimation, handling occlusions, capturing intricate details, and maintaining resilience in the face of varying lighting conditions and object textures. Moreover, achieving consistent and precise reconstructions across diverse object categories and scenes remains a substantial challenge.
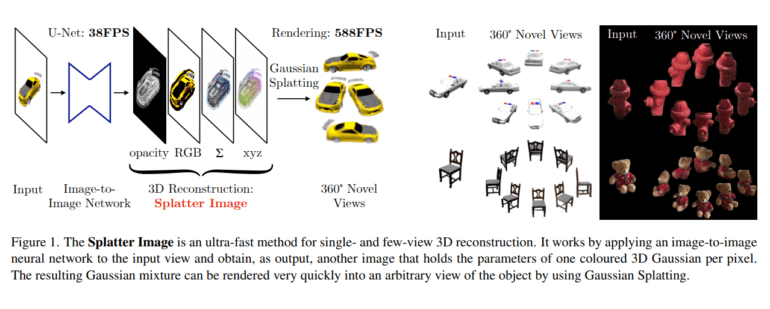
Enter the groundbreaking “Splatter Image” technique, introduced by researchers at the University of Oxford. This revolutionary approach leverages Gaussian Splatting as its foundational 3D representation, harnessing its lightning-fast rendering capabilities and superior output quality. At its core, the method envisions a 3D Gaussian entity for every pixel within the input image, powered by a state-of-the-art image-to-image neural network.
Crucially, despite only having access to a single side of the object during training, the Splatter Image technique can conjure a complete 360-degree reconstruction. This feat is achieved by encoding comprehensive information representing the entire panoramic view within the 2D image. Distinct Gaussians are assigned to specific 2D regions, each corresponding to sections of the 3D object. The researchers’ findings further reveal that many of these Gaussians remain inactive in practical scenarios, allowing for their efficient removal through post-processing methods.
What truly sets this model apart is its exceptional efficiency. Unlike other approaches that require distributed training across multiple GPUs, Splatter Image can be trained on a single GPU using standard 3D object benchmarks. Moreover, the researchers have expanded the capabilities of Splatter Image to accommodate multiple views as input. This extension entails the consolidation of Gaussian mixtures predicted from individual views, aligning them to a common reference, and amalgamating them to form a cohesive representation.
In a departure from existing methods, the Splatter Image technique anticipates a 3D Gaussian blend through a straightforward, forward-moving process. As a result, it excels in rapid inference, achieving real-time rendering capabilities while consistently delivering top-tier image quality across various metrics in the widely recognized single-view reconstruction benchmark.
Conclusion:
The introduction of the Splatter Image technique by Oxford researchers marks a significant milestone in the realm of monocular 3D object reconstruction. This innovative approach not only overcomes longstanding challenges but also sets new standards for efficiency, accuracy, and real-time capabilities. As computer vision continues to evolve, the Splatter Image technique stands as a shining example of cutting-edge research with profound implications for a multitude of industries and applications.