
TL;DR:
- InternVL bridges the gap in multi-modal AGI by aligning vision and language effectively.
- It outperforms existing models in 32 visual-linguistic benchmarks.
- InternVL’s architecture includes a 6 billion parameter vision encoder and an 8 billion parameter language middleware.
- The model uses a progressive alignment strategy for training.
- InternVL excels in image and video classification, retrieval, captioning, question answering, and multimodal dialogue.
- Its aligned feature space with Language Model Models enhances integration possibilities.
Main AI News:
In the realm of artificial intelligence, the convergence of vision and language has emerged as a critical frontier, with Language Model Models (LLMs) leading the way in recent advancements. However, there remains a substantial gap in the development of foundation models for vision and vision-language integration, hindering the progress of multi-modal Artificial General Intelligence (AGI) systems. Addressing this challenge head-on, a team of researchers from prestigious institutions, including Nanjing University, OpenGVLab, Shanghai AI Laboratory, The University of Hong Kong, The Chinese University of Hong Kong, Tsinghua University, University of Science and Technology of China, and SenseTime Research, introduces InternVL—a groundbreaking model that not only scales up vision foundation models but also aligns them for versatile visual-linguistic tasks.
InternVL is a solution designed to tackle the disparity in the development pace between vision foundation models and LLMs. Conventional models often employ basic glue layers to bridge the gap between vision and language features. Unfortunately, this approach results in parameter scale mismatches and representation inconsistencies, limiting the potential of LLMs.
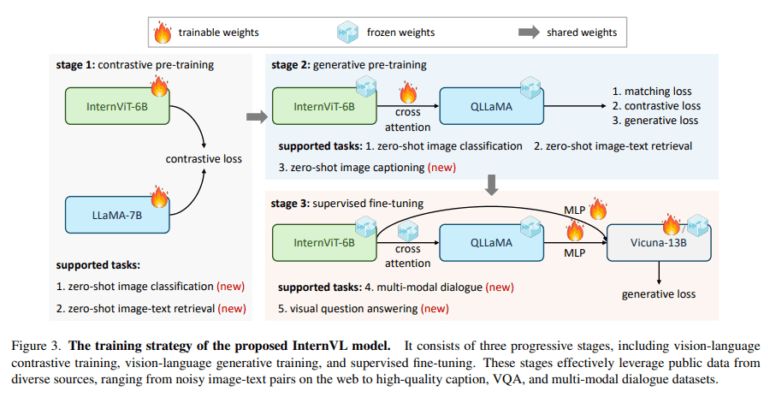
The methodology underpinning InternVL is both innovative and robust. At its core, the model leverages a large-scale vision encoder, InternViT-6B, complemented by a language middleware, QLLaMA, boasting a staggering 8 billion parameters. This architecture serves a dual purpose: it functions as an autonomous vision encoder for perception tasks while collaborating seamlessly with the language middleware for intricate vision-language tasks and multimodal dialogue systems. The model’s training employs a progressive alignment strategy, beginning with contrastive learning on extensive noisy image-text data and subsequently transitioning to generative learning using more refined data. This progressive approach consistently elevates the model’s performance across a spectrum of tasks.
InternVL showcases its prowess by outperforming existing methods across 32 generic visual-linguistic benchmarks—an indisputable testament to its advanced visual capabilities. The model excels in a myriad of tasks, ranging from image and video classification to image and video-text retrieval, image captioning, visual question answering, and multimodal dialogue. This diverse skill set is a direct result of its aligned feature space with LLMs, enabling the model to tackle complex tasks with unparalleled efficiency and precision.
Key Highlights of InternVL’s Performance:
- Versatility: InternVL functions adeptly as both a standalone vision encoder and when combined with the language middleware for a wide array of tasks.
- Scalability: InternVL pushes the boundaries by scaling the vision foundation model to a remarkable 6 billion parameters, facilitating comprehensive integration with LLMs.
- State-of-the-Art Performance: The model consistently achieves top-tier performance across 32 generic visual-linguistic benchmarks, underscoring its cutting-edge visual capabilities.
- Diverse Capabilities: InternVL excels in tasks such as image and video classification, image and video-text retrieval, image captioning, visual question answering, and multimodal dialogue.
- Seamless Integration: The aligned feature space with LLMs enhances its capacity to seamlessly integrate with existing language models, broadening its application scope.
InternVL stands as a testament to the relentless pursuit of excellence in the field of multi-modal AGI, offering a glimpse into the future of AI, where vision and language harmoniously converge for transformative applications.
Conclusion:
InternVL’s emergence signifies a significant step forward in the multi-modal AGI landscape. With its impressive performance and versatile capabilities, it is poised to drive innovation across various industries, enabling more seamless and efficient integration of vision and language in AI applications. This model has the potential to revolutionize the market by opening up new possibilities for complex visual-linguistic tasks and expanding the scope of AI-driven solutions.