
TL;DR:
- Microsoft researchers introduce CodeOcean and WaveCoder, pioneering improved instruction data generation.
- CodeOcean is a dataset with 20,000 instruction instances across four code-related tasks.
- WaveCoder is a fine-tuned Code LLM designed for enhanced instruction tuning.
- The approach leverages Large Language Models (LLMs) and aligns with recent advancements.
- It emphasizes the importance of data quality and diversity in instruction tuning.
- WaveCoder consistently outperforms other models across various benchmarks.
Main AI News:
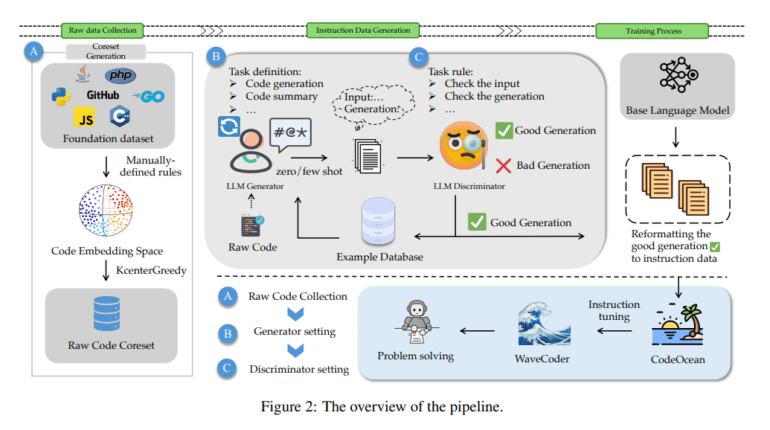
In a groundbreaking development, researchers at Microsoft have unveiled an innovative approach to harnessing diverse, high-quality instruction data from open-source code. This advancement promises to revolutionize instruction tuning and enhance the generalization capabilities of fine-tuned models. It aims to address the challenges associated with instruction data generation, including the presence of duplicate data and limited control over data quality. The solution at hand involves a robust method that categorizes instruction data into four universal code-related tasks, and it introduces a Language Model (LLM) based Generator-Discriminator data processing framework known as CodeOcean.
CodeOcean, a meticulously curated dataset, emerges as the centerpiece of this research, comprising a staggering 20,000 instruction instances across four critical code-related tasks: Code Summarization, Code Generation, Code Translation, and Code Repair. Its primary objective is to elevate the performance of Code LLMs through precision instruction tuning. The research endeavor also introduces WaveCoder, a finely-tuned Code LLM endowed with Widespread And Versatile Enhanced instruction tuning capabilities. WaveCoder has been meticulously designed to amplify the potency of instruction tuning for Code LLMs, offering unparalleled generalization abilities across various code-related tasks, surpassing other open-source models at an equivalent fine-tuning scale.
This groundbreaking research capitalizes on recent advancements in Large Language Models (LLMs), underscoring the immense potential of instruction tuning in augmenting model capabilities across a spectrum of tasks. Instruction tuning has been validated as an effective strategy for enhancing the generalization prowess of LLMs in diverse contexts, as exemplified by previous studies such as FLAN, ExT5, and FLANT5. The research introduces the concept of alignment, wherein pre-trained models, honed through self-supervised tasks, can grasp the nuances of text inputs. Instruction tuning brings instruction-level tasks into the spotlight, allowing pre-trained models to extract richer information from instructions and elevate their interactivity with users to unprecedented levels.
Existing methodologies for generating instructional data, such as self-instruct and evol-instruct, have traditionally relied on the performance of teacher LLMs and have occasionally given rise to duplicated data. In stark contrast, the proposed LLM Generator-Discriminator framework leverages source code, affording explicit control over data quality during the generation process. This methodology excels in generating more authentic instruction data by taking raw code as its starting point and selecting a core dataset while meticulously modulating data diversity through adjustments in raw code distribution.
The study strategically classifies instruction instances into four distinct code-related tasks and refines the instruction data, culminating in the creation of CodeOcean. To further elevate performance, the authors introduce WaveCoder models, fine-tuned with the invaluable CodeOcean dataset, and demonstrate their remarkable generalization capabilities vis-à-vis other open-source models. WaveCoder emerges as a highly efficient performer in code generation tasks, making substantial contributions to instruction data generation and fine-tuning models, thereby yielding remarkable improvements in code-related task performance.
WaveCoder models consistently outshine their counterparts across a plethora of benchmarks, including HumanEval, MBPP, and HumanEvalPack. This research underscores the pivotal role of data quality and diversity in the instruction-tuning process. The exemplary performance of WaveCoder is rigorously evaluated across various domains, encompassing code generation, repair, and summarization tasks, reaffirming its efficacy in diverse scenarios. A head-to-head comparison with the CodeAlpaca dataset unequivocally underscores the superiority of CodeOcean in refining instruction data and elevating the instruction-following acumen of base models.
Conclusion:
Microsoft’s CodeOcean and WaveCoder represent a significant leap in the field of instruction tuning for code language models. This innovation enhances data quality and diversity, ensuring superior performance across diverse code-related tasks. For the market, this signifies a new era of more capable and adaptable code language models, offering improved solutions for a range of applications and industries.