
TL;DR:
- CLOVA, a closed-loop AI framework, addresses the challenge of adaptable visual assistants in the dynamic AI landscape.
- Traditional models lack adaptability, hindering their effectiveness in evolving environments.
- CLOVA introduces a dynamic three-phase approach: inference, reflection, and learning, breaking free from static methodologies.
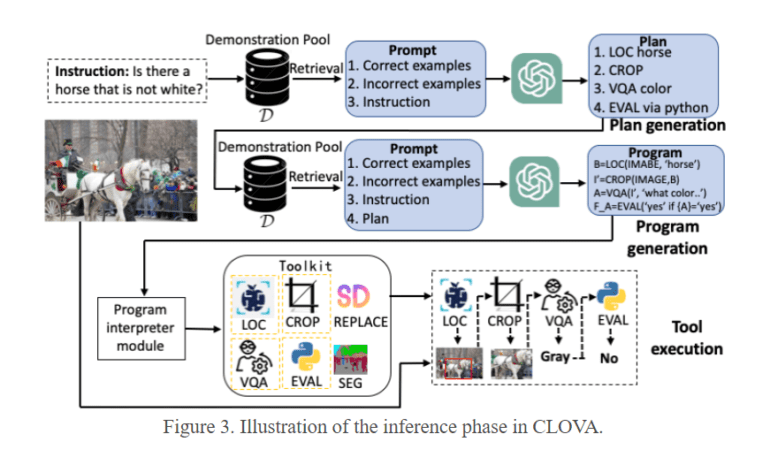
- During inference, CLOVA incorporates both correct and incorrect examples, optimizing precision in plan and program generation.
- CLOVA’s multimodal global-local reflection scheme enhances tool identification and updates with exceptional accuracy.
- Real-time data collection and prompt-tuning in the learning phase prevent catastrophic forgetting, making CLOVA adaptable to new challenges.
- The system employs three data collection strategies, ensuring a current and relevant knowledge base.
Main AI News:
In the ever-evolving realm of Artificial Intelligence, the demand for adaptable and versatile visual assistants has never been greater. Traditional AI models, with their static capabilities, struggle to keep pace with the dynamic nature of modern tasks and environments. Enter CLOVA, a groundbreaking closed-loop AI framework introduced by a collaborative team from Peking University, BIGAI, Beijing Jiaotong University, and Tsinghua University. This innovative framework promises to redefine the landscape of visual intelligence by offering agility and responsiveness like never before.
The Achilles’ heel of current visual assistant models is their lack of adaptability. As tasks and environments evolve, these models often find themselves obsolete. CLOVA, however, takes a radically different approach. It embraces a dynamic three-phase strategy encompassing inference, reflection, and learning, breaking free from the limitations of static methodologies and propelling visual intelligence into a new era.
During the inference phase, CLOVA departs from convention by incorporating both correct and incorrect examples, a stark contrast to traditional models relying solely on accuracy. This approach enables CLOVA to optimize the generation of precise plans and programs, setting a new standard in visual intelligence. Additionally, CLOVA employs a multimodal global-local reflection scheme, enhancing its ability to pinpoint and update specific tools with unparalleled accuracy, truly setting it apart from the competition.
CLOVA’s real-time data collection strategy and prompt-tuning mechanism in the learning phase address a common challenge faced by traditional models: catastrophic forgetting. By updating its tools based on real-time reflections, CLOVA ensures it retains knowledge while adapting to new challenges. This adaptability is demonstrated across various tasks, establishing CLOVA as a formidable player in the dynamic visual assistant landscape. The system employs three distinct methods for data collection, utilizing language models for specific tasks, leveraging open-vocabulary datasets for localization and segmentation tools, and searching the internet for select tools. These strategies combine to maintain a current and relevant knowledge base, further solidifying CLOVA’s position as a game-changer in the field of visual assistance.
Conclusion:
CLOVA’s closed-loop AI framework represents a significant leap forward in the quest for adaptable visual assistants. Its dynamic approach, innovative methodologies, and real-time learning capabilities position it as a trailblazer in the rapidly evolving world of Artificial Intelligence. CLOVA is set to unlock the full potential of visual intelligence, offering a brighter and more adaptable future for AI-powered visual assistants.