
TL;DR:
- LLMs are pivotal in AI applications, but managing computational costs is a challenge.
- MosaicML introduces innovative Chinchilla scaling laws that consider training and inference costs.
- Their approach recommends smaller models trained for longer durations for cost-effectiveness.
- Smaller, more efficiently trained models reduce computational expenses, making LLMs more viable.
Main AI News:
In the realm of Artificial Intelligence, Large Language Models (LLMs) have emerged as powerful tools, revolutionizing various applications such as automated translation and conversational agents. These marvels of technology, however, come with a challenge – striking the right balance between enhancing capabilities and managing computational costs.
The pivotal question that haunts LLM advancement is optimizing the model’s scale, considering its size and training data. The ultimate goal is to enhance performance without burdening organizations with exorbitant computational expenses. Traditionally, increasing the model size has shown promise in improving performance, but it has been accompanied by escalating training and inference costs. Thus, finding an efficient way to scale LLMs, one that harmonizes quality and computational expenditure, has become a paramount concern.
The predominant approach to scaling LLMs has hitherto been guided by established scaling laws, notably the Chinchilla scaling laws devised by DeepMind. These laws provide a blueprint for increasing model parameters and training data to boost quality. However, there’s a blind spot in their focus – they primarily address the computational costs during the training phase, while overlooking the significant expenses incurred during the model’s inference stage.
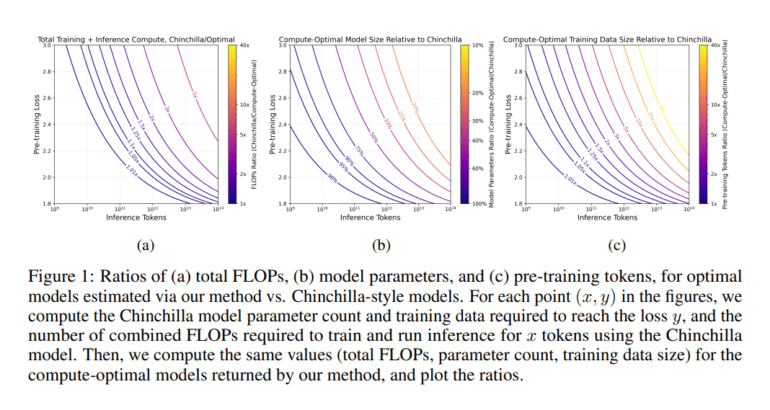
Enter MosaicML, with its groundbreaking approach to scaling LLMs that takes into account both training and inference costs. The modified Chinchilla scaling laws proposed by MosaicML aim to strike the perfect equilibrium between model parameters, pre-training data size, and overall model quality, while factoring in the costs associated with both training and inference phases. This represents a seismic shift from traditional scaling practices, prioritizing a holistic view of computational expenses.
At the core of this innovative approach is a comprehensive analysis of the trade-off between training and inference costs. MosaicML’s researchers have devised a new formula to calculate the optimal size for LLMs, particularly when faced with substantial inference demands. This formula suggests training models with fewer parameters for extended durations, a deviation from Chinchilla’s scaling laws, which traditionally advocated for the opposite. The aim? Achieving a harmonious balance that alleviates the overall computational burden without compromising the model’s performance.
The study’s findings paint a compelling picture – smaller, efficiently trained models become increasingly cost-effective as inference demands soar. Take, for instance, a model with the quality of a Chinchilla-7B, operating under high inference demand. MosaicML’s strategic adjustments recommend optimizing it with fewer parameters and a greater volume of data. This tactical shift results in a remarkable reduction in total computational costs, making the deployment of LLMs not only more efficient but also economically viable.
Conclusion:
MosaicML’s innovative approach to LLM scaling, considering both training and inference costs, is poised to revolutionize the AI market. Organizations can now harness the power of language models more efficiently, making AI applications more accessible and economically viable. This shift towards efficiency will likely drive increased adoption of LLMs in various industries, spurring further innovation and growth in the AI market.