
TL;DR:
- LLM AutoEval streamlines language model evaluation in Google Colab.
- It offers automated setup, customizable parameters, and GitHub integration.
- Two benchmark suites, “nous” and “openllm,” cater to diverse evaluation needs.
- Troubleshooting guidance is provided for common issues.
- Users must create secrets for RunPod and GitHub token integration.
- The tool’s user-friendly interface simplifies the evaluation process.
Main AI News:
In the ever-evolving landscape of Natural Language Processing, the evaluation of Language Models (LLMs) stands as a pivotal step in advancing the frontiers of language understanding and generation. Enter LLM AutoEval, an innovative platform designed to revolutionize and expedite the process of evaluating Language Models, bringing unprecedented ease and efficiency to the developers’ toolkit.
LLM AutoEval has been meticulously crafted with developers in mind, offering a streamlined approach to LLM performance assessment. This groundbreaking tool comes with an array of indispensable features, making it a game-changer in the field:
- Automated Setup and Execution: LLM AutoEval simplifies the setup and execution process with the integration of RunPod. This seamless deployment via Google Colab notebooks ensures developers can hit the ground running effortlessly.
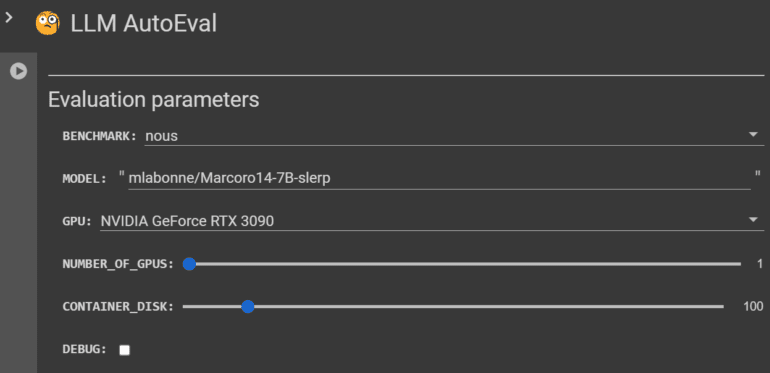
- Customizable Evaluation Parameters: Recognizing the unique requirements of each evaluation, LLM AutoEval empowers developers with the flexibility to fine-tune their assessment. Choose from two benchmark suites – nous or openllm – to tailor the evaluation precisely to your needs.
- Summary Generation and GitHub Gist Upload: Efficiency is at the core of LLM AutoEval. After evaluation, the tool automatically generates a concise summary of the results, offering a snapshot of the model’s performance. This summary can be effortlessly uploaded to GitHub Gist, facilitating easy sharing and future reference.
LLM AutoEval prioritizes user-friendliness, offering a highly customizable interface that caters to the diverse needs of developers engaged in assessing Language Model performance. Let’s delve deeper into what makes it exceptional:
- Benchmark Suites: LLM AutoEval presents two distinct benchmark suites, namely “nous” and “openllm,” each serving specific evaluation needs. The “nous” suite encompasses tasks like AGIEval, GPT4ALL, TruthfulQA, and Bigbench, providing a comprehensive evaluation experience. In contrast, the “openllm” suite includes tasks like ARC, HellaSwag, MMLU, Winogrande, GSM8K, and TruthfulQA, harnessing the power of the vllm implementation for enhanced speed.
- Customization Options: Developers have the freedom to fine-tune their evaluation process, selecting a specific model ID from Hugging Face, choosing their preferred GPU, specifying the number of GPUs, and setting the container disk size. Furthermore, developers can opt for either the community or secure cloud on RunPod and toggle the trust remote code flag for models like Phi. While a debug mode is available, it’s advisable to exercise caution when keeping the pod active post-evaluation.
To seamlessly integrate tokens into LLM AutoEval, users must access Colab’s Secrets tab, where they can create two secrets named “runpod” and “github,” containing the essential tokens for RunPod and GitHub, respectively.
LLM AutoEval distinguishes itself further through its benchmark suites, catering to distinct evaluation needs:
- Nous Suite: Developers can benchmark their LLMs against models like OpenHermes-2.5-Mistral-7B, Nous-Hermes-2-SOLAR-10.7B, or Nous-Hermes-2-Yi-34B. Teknium’s LLM-Benchmark-Logs provide valuable reference points for comprehensive comparisons.
- Open LLM Suite: This suite broadens the horizon, enabling developers to benchmark their models against the models listed on the Open LLM Leaderboard, fostering a more extensive comparison within the developer community.
LLM AutoEval simplifies troubleshooting with clear guidance for common issues. For instance, if you encounter the “Error: File does not exist” scenario, the tool recommends activating debug mode and rerunning the evaluation, allowing users to inspect logs for missing JSON files. In cases of the “700 Killed” error, a cautionary note advises users on the potential hardware limitations, particularly when running the Open LLM benchmark suite on GPUs like the RTX 3070. Lastly, for outdated CUDA drivers, initiating a new pod is recommended to ensure compatibility and smooth operation of the LLM AutoEval tool.
Conclusion:
LLM AutoEval is poised to become an indispensable asset for developers in the field of Natural Language Processing, simplifying and accelerating the evaluation of Language Models in Google Colab. With its automated setup, customizable parameters, and user-friendly interface, it’s set to reshape the way developers assess and refine their models, ushering in a new era of efficiency and innovation. Stay tuned for more updates on this groundbreaking tool as it continues to evolve and empower the NLP community.