
TL;DR:
- Mixtral 8x7B, a groundbreaking language model by Mistral AI, introduces Sparse Mixture of Experts (SMoE) with open weights.
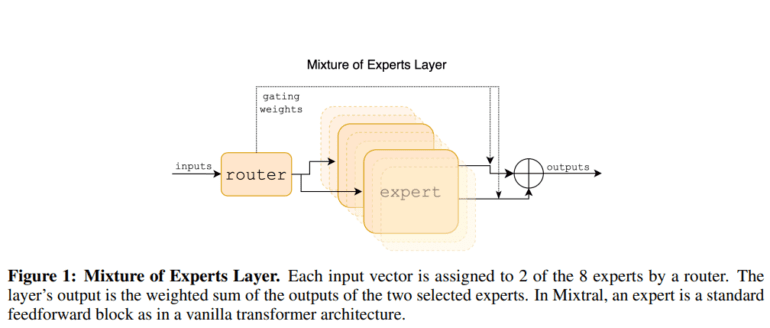
- Mixtral’s feedforward block utilizes eight parameter groups, optimizing each layer and token with dynamically selected experts.
- Efficient parameter usage in Mixtral enhances model capabilities while maintaining cost and latency control.
- Pre-trained with a 32k token context size, Mixtral rivals or outperforms Llama 2 70B and GPT-3.5 in various benchmarks.
- Multilingual understanding, code production, and mathematics are areas where Mixtral excels.
- Mixtral effectively retrieves data from its 32k token context window, regardless of data length or position.
- Rigorous benchmarks include mathematics, code analysis, reading comprehension, common-sense reasoning, world knowledge, and more.
- Mixtral 8x7B – Instruct, an instructional conversation model, outperforms other chat models in human review benchmarks.
- Both Mixtral 8x7B and Mixtral 8x7B – Instruct are licensed under Apache 2.0, promoting widespread commercial and academic use.
- The incorporation of Megablocks CUDA kernels enhances inference efficiency in Mixtral.
Main AI News:
Mistral AI, a pioneering force in the realm of artificial intelligence, has unveiled the transformative Mixtral 8x7B. This cutting-edge language model is built upon the innovative Sparse Mixture of Experts (SMoE) framework, boasting open weights that empower it to redefine the landscape of machine learning. Released under the Apache 2.0 license, Mixtral stands as a beacon of progress in the form of a decoder model.
The architects behind Mixtral’s formidable capabilities have meticulously crafted its feedforward block, drawing from a pool of eight distinct parameter groups. Each layer and token within the model is endowed with two parameter groups, aptly named experts. These experts are dynamically selected by the router network to process tokens and seamlessly amalgamate their outcomes through additive processes. By harnessing only a fraction of the total parameters for each token, Mixtral ingeniously expands the model’s parameter space, all the while upholding stringent cost and latency controls.
Mistral’s data-driven approach is manifest in Mixtral’s extensive pre-training, which leverages multilingual data with an expansive 32k token context size. In empirical benchmarks, Mixtral has consistently rivaled, and in many cases, surpassed the capabilities of Llama 2 70B and GPT-3.5. One of its most remarkable attributes lies in its optimal utilization of parameters, endowing it with the ability to deliver rapid inferences with small batch sizes and enhanced throughput in large batch settings.
Mixtral’s prowess truly shines when it comes to multilingual comprehension, code generation, and mathematical problem-solving. Rigorous experiments have demonstrated Mixtral’s remarkable ability to extract valuable insights from its expansive context window of 32k tokens, irrespective of data length or position within the sequence.
To ensure a comprehensive and equitable assessment, the Mistral AI team conducted a thorough evaluation of the Mixtral and Llama models. The evaluation encompassed a diverse array of challenges, categorized into areas such as mathematics, code analysis, reading comprehension, common-sense reasoning, world knowledge, and consolidated research findings.
Common-sense reasoning assessments, including ARC-Easy, ARC-Challenge, Hellaswag, Winogrande, PIQA, SIQA, OpenbookQA, and CommonsenseQA, were conducted in a 0-shot environment. Tasks related to world knowledge, such as TriviaQA and NaturalQuestions, were evaluated in a 5-shot format. Reading comprehension tests encompassed BoolQ and QuAC, conducted in a 0-shot setting. Mathematical tasks included GSM8K and MATH, while code-related challenges featured Humaneval and MBPP. Additionally, the research incorporated popular aggregated findings from AGI Eval, BBH, and MMLU.
The study also introduces Mixtral 8x7B – Instruct, a conversation model meticulously optimized for instructional purposes. A combination of direct preference optimization and supervised fine-tuning techniques were employed in its development. In human review benchmarks, Mixtral – Instruct has consistently outperformed formidable counterparts such as GPT-3.5 Turbo, Claude-2.1, Gemini Pro, and Llama 2 70B – chat model. Notably, benchmarks like BBQ and BOLD have revealed fewer biases and a more balanced sentiment profile within Mixtral – Instruct.
To foster widespread accessibility and encourage a myriad of applications, both Mixtral 8x7B and Mixtral 8x7B – Instruct have been licensed under the Apache 2.0 license, extending their availability for both commercial and academic utilization. The team’s commitment to efficiency is evident through the incorporation of Megablocks CUDA kernels, enhancing the model’s prowess in effective inference. The vLLM project has been skillfully modified to accommodate these innovations, ensuring that Mixtral remains at the forefront of the AI revolution.
Conclusion:
Mixtral 8x7B’s introduction marks a significant leap in language model technology, offering enhanced efficiency, versatility, and performance across various applications. Its potential to excel in multilingual comprehension, code generation, and mathematics positions it as a game-changer in the AI market, appealing to both commercial and academic users. The efficient parameter utilization and reduced biases in Mixtral 8x7B – Instruct further solidify its relevance in the ever-evolving landscape of artificial intelligence.