
TL;DR:
- Linear Attention, a computational powerhouse, faces challenges due to cumulative summation (cumsum).
- The research employs the “kernel trick” and innovative techniques to optimize Linear Attention.
- Lightning Attention-2 emerges as a breakthrough, dividing computations using tiling.
- Experiments confirm Lightning Attention-2’s superior performance and computational advantages.
- Implementation in Triton enhances efficiency, surpassing other attention mechanisms.
- Lightning Attention-2 holds potential for large language models handling extended sequences.
Main AI News:
In the realm of sequence processing, the quest for optimizing attention mechanisms with computational efficiency has been a perpetual challenge. Enter Linear Attention, a game-changing mechanism renowned for its prowess in handling tokens with linear computational complexities. It has recently emerged as a formidable contender to the conventional softmax attention. The standout feature? Its ability to conquer sequences of boundless length while maintaining a steadfast training pace and unchanging memory footprint. However, there is a stumbling block – the cumulative summation (cumsum), which has hindered the full realization of Linear Attention’s efficiency in everyday scenarios.
The ongoing research in this field has delved into leveraging the “kernel trick” to expedite the computation of attention matrices. It places a premium on the product of keys and values before embarking on the n×n matrix multiplication journey. Lightning Attention-1 made strides in addressing the computational lag in Linear Attention by segmenting inputs and sculpting attention output within blocks. Pioneering techniques like the 1 + elu activation, cosine function approximation, and savvy sampling strategies have been employed to mimic the workings of softmax operation. Meanwhile, IO-aware Attention has cast its spotlight on system-level optimizations for implementing the standard attention operator adeptly on GPU platforms. Some ingenious minds have ventured to extend the context window sizes directly, exemplified by Position Interpolation (PI) and the visionary StreamingLLM, aiming to elongate sequence lengths in LLMs.
And now, the stage is set for the grand debut of Lightning Attention-2, a remarkable linear attention mechanism primed to handle sequences of limitless proportions without a hint of compromise in speed. It achieves this feat through the judicious application of tiling, effectively segregating computations into intra-block and inter-block components. Lightning Attention-2 is the answer to the nagging limitations that have plagued existing linear attention algorithms, particularly the vexing issues tied to cumulative summation. It represents a monumental breakthrough for colossal language models that grapple with processing extensive sequences.
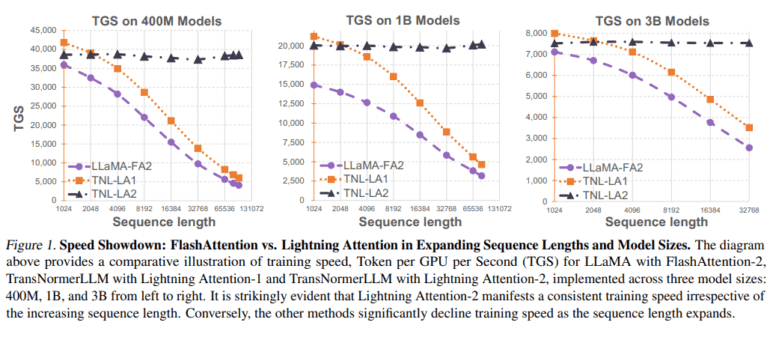
A battery of experiments, spanning diverse model sizes and sequence lengths, have unequivocally validated the remarkable performance and computational supremacy of Lightning Attention-2. The incorporation of Lightning Attention-2 into Triton transforms it into an IO-aware and hardware-friendly powerhouse, elevating its efficiency to unprecedented heights. This algorithm boasts unwavering training and inference speeds, regardless of the sequence lengths thrown at it. It not only outpaces its attention mechanism counterparts in both speed and accuracy but also confronts the cumulative summation challenge head-on, ushering in a new era for large language models navigating extended sequences.
Conclusion:
Lightning Attention-2 emerges as a beacon of hope in the realm of linear attention, conquering the computational hurdles in the everyday setting. With its “divide and conquer” approach and the strategic use of tiling techniques, this innovation stands tall against the prevailing constraints, especially the cumsum conundrum. With its unwavering training speeds and capacity to outshine existing attention mechanisms, Lightning Attention-2 holds the promise of propelling large language models, especially those entrusted with managing sprawling sequences, to unprecedented horizons. The horizon beckons, with the prospect of incorporating sequence parallelism to conquer the challenges posed by contemporary hardware limitations.