
TL;DR:
- AI models powered by extensive training data from web scraping rely heavily on Machine Translation (MT).
- Multi-way translations in various languages indicate MT usage in web content.
- Research explores the impact of low-cost MT on the web and large multi-lingual language models (LLMs).
- A Novel Multi-Way ccMatrix (MWccMatrix) dataset was created to analyze web content.
- The methodology involves prioritizing sentence pairs in ccMatrix based on LASER margin score.
- Findings reveal the prevalence of MT across the web, especially in low-resource languages.
- Multi-way translations exhibit lower quality compared to 2-way translations.
- Multi-way parallel data contains shorter, predictable sentences, often related to conversation and opinions.
- This affects the fluency and accuracy of multi-lingual LLMs, leading to more biases and hallucinations.
- Low-quality content is produced for ad revenue, impacting data quality in lower-resource languages.
Main AI News:
In the realm of Artificial Intelligence (AI), the driving force behind cutting-edge models often lies in the vast expanse of training data, ranging from billions to trillions of tokens, all of which are made accessible through web scraping. This treasure trove of web content is subsequently translated into multiple languages, and the quality of these multi-way translations strongly indicates their origin in Machine Translation (MT) systems. This research endeavor delves into the profound influence wielded by cost-effective MT on the web and the intricate world of large multi-lingual language models (LLMs).
While previous studies have detected the presence of MT in web corpora, only a select few have delved into the intricacies of multi-way parallelism. The authors of this research paper belong to this exclusive group, employing a similar approach in their exploration. Their research journey led to the creation of translation tuples, each comprising two or more sentences in different languages, all corresponding to translations of one another. This valuable dataset is aptly named the Multi-Way ccMatrix (MWccMatrix).
The methodology involved in this research is meticulous, encompassing the exhaustive examination of sentence pairs within the ccMatrix, constructed by embedding web-scraped sentences into a multi-lingual space. These pairs are then prioritized based on the LASER margin score, and new pairs are seamlessly integrated into the MWccMatrix dataset. Notably, the researchers have taken steps to ensure the deduplication of the corpus, ensuring that each distinct sentence finds its place in the dataset just once. While repetition of sentences is diligently avoided, the dataset does allow for near-duplicates, primarily differing in punctuation or capitalization.
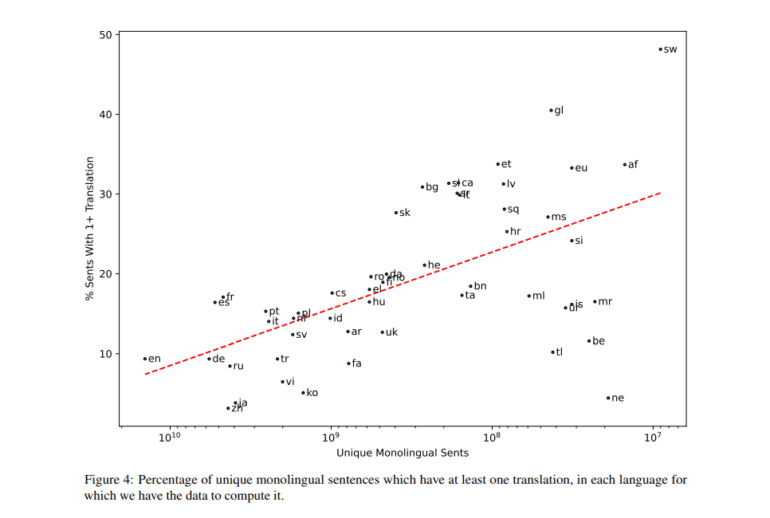
The overarching analysis of this research underscores the pervasive nature of MT across the web landscape. A stark comparison was drawn between the total number of unique sentences in the MWccMatrix and those within the Common Crawl dataset. It revealed that languages like English and French boast a substantial percentage of unique sentences, each with at least one corresponding translation (9.4% and 17.5%, respectively). Moreover, it was established that web-based translations exhibit a remarkable degree of multi-way parallelism, with low-resource languages exhibiting an average parallelism rate of 8.6. Intriguingly, these multi-way translations exhibit a distinct decline in quality when compared to their 2-way parallel counterparts.
Furthermore, the research findings shed light on the characteristic attributes of multi-way parallel data. It is observed that this data predominantly comprises shorter and more predictable sentences, often centered around conversational and opinion-based topics. This unique characteristic has a profound impact on the fluency and precision of multi-lingual LLMs, leading to an increased occurrence of hallucinations and bias. The researchers argue that the selection bias is a consequence of the prevalence of low-quality content, likely generated with the aim of maximizing ad revenue. As a result, data is translated into numerous lower-resource languages to target a wider audience, ultimately compromising its overall quality and integrity.
Conclusion:
The widespread use of Machine Translation in web content, especially in low-resource languages, has significant implications for the market. Businesses operating in the global digital space need to be cautious about the quality and accuracy of translated content, as it can impact user experience, trust, and brand reputation. Investing in high-quality translation services and tools becomes imperative to maintain a competitive edge and ensure a positive market presence.