
TL;DR:
- FedTabDiff is a cutting-edge AI model designed for generating high-quality mixed-type tabular data while prioritizing privacy.
- Privacy concerns in finance and healthcare have hindered AI model deployment, making privacy preservation essential.
- Traditional methods like anonymization fall short, but FedTabDiff introduces synthetic data generation through Denoising Diffusion Probabilistic Models (DDPMs).
- It employs a federated learning approach, allowing collaborative model training while respecting data privacy.
- Evaluation metrics encompass fidelity, utility, privacy, and coverage, demonstrating superior performance across financial and medical datasets.
- FedTabDiff holds promise for responsible and privacy-preserving AI applications in finance and healthcare.
Main AI News:
In the realm of generating authentic tabular data, one of the foremost challenges faced by researchers revolves around the critical issue of privacy, particularly within sensitive domains such as finance and healthcare. As the sheer volume of data and the significance of data analysis continue to surge across all sectors, apprehensions surrounding privacy have cast a shadow over the deployment of AI models. Thus, the imperative of safeguarding privacy has risen in tandem with these developments. In the realm of finance, safeguarding privacy encounters formidable obstacles, including the presence of mixed attribute types, implicit relationships, and skewed distributions within real-world datasets.
Enter a groundbreaking solution crafted by a collaborative team hailing from the University of St. Gallen in Switzerland, Deutsche Bundesbank in Germany, and the International Computer Science Institute in the USA. This innovation, known as FedTabDiff, introduces a method that empowers the generation of high-fidelity mixed-type tabular data without the need for centralized access to original datasets. In doing so, it not only ensures privacy but also aligns seamlessly with stringent regulations such as the EU’s General Data Protection Regulation and the California Privacy Rights Act.
In contrast to traditional methods like anonymization and sensitive attribute elimination, which often fall short in high-stakes domains, FedTabDiff introduces the concept of synthetic data. This involves generating data through a generative process rooted in the inherent characteristics of real data. The researchers harness the power of Denoising Diffusion Probabilistic Models (DDPMs), renowned for their success in generating synthetic images, and ingeniously apply this concept within a federated framework for tabular data generation.
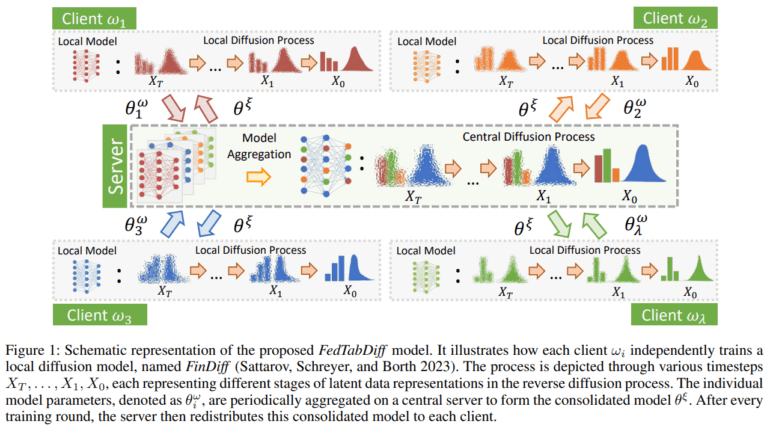
FedTabDiff seamlessly integrates DDPMs into a federated learning paradigm, allowing multiple entities to collaboratively train a generative model, all while respecting data privacy and locality. DDPMs employ a Gaussian Diffusion Model, employing a forward process that progressively perturbs data with Gaussian noise before meticulously restoring it through a reverse process. The federated learning component incorporates a synchronous update scheme and weighted averaging to ensure effective model aggregation. The architecture of FedTabDiff encompasses a central FinDiff model maintained by a trusted entity, complemented by decentralized FinDiff models contributed by individual clients. This federated optimization strategy culminates in a weighted average over decentralized model updates, facilitating a harmonious and productive collaborative learning process. For model evaluation, the researchers employ standard metrics that encompass fidelity, utility, privacy, and coverage.
FedTabDiff stands out with its exceptional performance, demonstrating its efficacy across financial and medical datasets, thus underscoring its versatility in diverse scenarios. A comparative analysis against non-federated FinDiff models clearly illustrates its superiority across all four key metrics. Remarkably, it adeptly strikes a balance between preserving privacy and curbing deviations from the original data, effectively preventing data from veering into the realm of implausibility. The empirical evaluations conducted on real-world datasets underscore FedTabDiff’s potential for responsible and privacy-preserving AI applications, particularly within the pivotal domains of finance and healthcare.
Conclusion:
FedTabDiff presents a game-changing solution for privacy-conscious industries like finance and healthcare. By leveraging synthetic data generation and federated learning, it overcomes traditional privacy challenges, offering a powerful tool for responsible AI applications. This innovation has the potential to drive substantial market growth in privacy-sensitive domains, fostering trust in AI technology and enabling more widespread adoption.