
TL;DR:
- Large Language Models (LLMs) are crucial in cloud-based AI, but handling long-context text generation is challenging.
- Ali Baba Group and Shanghai Jiao Tong University introduce DistKV-LLM, utilizing DistAttention for efficient resource management.
- DistAttention segments Key-Value Cache, allowing distributed processing and storage, addressing long-context challenges.
- DistKV-LLM excels in managing KV Caches, orchestrating memory usage, and enhancing LLM service performance.
- DistKV-LLM achieves 1.03-2.4 times better throughput and supports context lengths up to 219 times longer than existing systems.
Main AI News:
The realm of natural language processing has experienced a remarkable transformation with the emergence of Large Language Models (LLMs). These sophisticated models have revolutionized the landscape of AI applications, offering a diverse range of capabilities, from generating text to solving complex problems and facilitating conversational AI. Their utility in cloud-based AI services is undeniable, given their intricate architectures and substantial computational demands. Nevertheless, integrating these LLMs into cloud environments comes with its own set of challenges, particularly in addressing the dynamic and iterative nature of auto-regressive text generation, especially when dealing with extensive contextual information. Conventional cloud-based LLM services often demand more efficient resource management to avoid performance degradation and resource wastage.
The core challenge arises from the dynamic character of LLMs, where each newly generated token becomes part of the existing text corpus, thus serving as input for recalibration within the LLM. This continual process demands significant and fluctuating memory and computational resources, creating substantial hurdles in designing efficient cloud-based LLM service systems. Existing approaches, such as PagedAttention, have attempted to mitigate these challenges by facilitating data exchange between GPU and CPU memory. However, they are constrained by the limitations of a single node’s memory and struggle to efficiently manage exceedingly long context lengths.
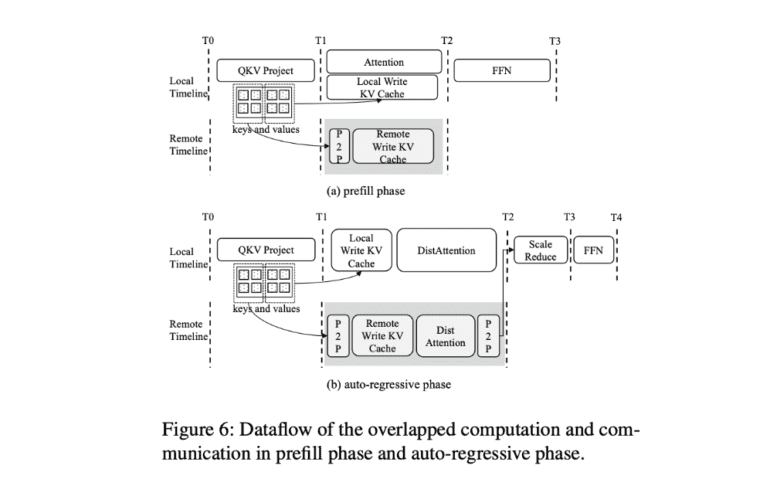
In response to these challenges, a collaboration between the Ali Baba Group and researchers from Shanghai Jiao Tong University introduces an innovative distributed attention algorithm known as DistAttention. This algorithm segments the Key-Value (KV) Cache into smaller, manageable units, enabling distributed processing and storage of the attention module. This segmentation proves exceptionally efficient in handling long context lengths, eliminating the performance fluctuations often associated with data swapping or live migration processes. The research paper introduces DistKV-LLM, a distributed LLM serving system that dynamically manages KV Cache and orchestrates the utilization of GPU and CPU memories across the entire data center.
DistAttention introduces a novel approach by breaking down traditional attention computation into smaller units termed macro-attentions (MAs) and their corresponding KV Caches (rBlocks). This approach empowers independent model parallelism strategies and memory management for attention layers in contrast to other layers within the Transformer block. DistKV-LLM excels in effectively managing these KV Caches, efficiently coordinating memory usage across distributed GPUs and CPUs throughout the data center. In cases where an LLM service instance faces memory shortages due to KV Cache expansion, DistKV-LLM proactively borrows additional memory from less burdened instances. This intricate protocol fosters efficient, scalable, and coherent interactions among numerous LLM service instances running in the cloud, thereby enhancing the overall performance and reliability of LLM services.
The results are impressive, with the system showcasing substantial improvements in end-to-end throughput, achieving 1.03-2.4 times better performance than existing state-of-the-art LLM service systems. Notably, it also supports context lengths up to 219 times longer than current systems, as evidenced by extensive testing across 18 datasets with context lengths extending up to 1,900K. These rigorous tests were conducted in a cloud environment equipped with 32 NVIDIA A100 GPUs, in configurations ranging from 2 to 32 instances. The enhanced performance can be attributed to DistKV-LLM’s ability to effectively orchestrate memory resources across the entire data center, ensuring a high-performance LLM service adaptable to a wide range of context lengths.
Conclusion:
The introduction of DistAttention and DistKV-LLM signifies a significant advancement in the cloud-based LLM service market. These innovations address crucial resource management challenges, leading to improved performance and scalability, making LLM services adaptable to a broader range of applications and context lengths. This breakthrough has the potential to drive increased adoption of LLM technology in various industries, further solidifying China’s role in AI research and development.