
TL;DR:
- Machine learning’s shift towards personalization is transforming various industries.
- Regulatory approval processes limit personalization in critical sectors like healthcare and autonomous driving.
- Technion researchers propose Represented Markov Decision Processes (r-MDPs) to streamline regulatory reviews.
- r-MDPs use deep reinforcement learning algorithms inspired by K-means clustering principles.
- These algorithms optimize policies for predefined assignments and assignments for a set of policies.
- r-MDPs achieve significant personalization with a constrained policy budget, outperforming existing methods in simulations.
- The approach promises safer, more effective, and tailored user experiences while complying with regulations.
Main AI News:
In the dynamic landscape of machine learning, personalization has emerged as a game-changer, with far-reaching implications across various industries, from recommender systems to healthcare and financial services. Personalization tailors decision-making processes to the individual’s unique characteristics, elevating user experiences and enhancing overall effectiveness. For instance, in the realm of recommender systems, algorithms adeptly suggest products or services by delving into an individual’s purchase history and browsing behavior. However, the application of this personalized approach to critical sectors like healthcare and autonomous driving faces a formidable challenge – navigating the intricate web of regulatory approval processes. These indispensable processes are the guardians of safety and efficacy in ML-driven products, yet they present a formidable bottleneck when deploying personalized solutions in high-stakes environments.
The quandary of integrating personalization into high-risk domains isn’t rooted in the acquisition of data or technological limitations; rather, it resides in the protracted and rigorous regulatory review processes. These processes, epitomized by the exhaustive evaluations undergone by-products such as the Artificial Pancreas in healthcare, underscore the intricacy of harmonizing personalized ML solutions with sectors where errors can yield dire consequences. The crux of the matter lies in striking the delicate balance between the imperative for individualized solutions and the procedural rigidity of regulatory approvals – a task of extraordinary complexity, particularly in fields characterized by high stakes and costly errors.
Enter Technion’s visionary researchers, who have proffered a groundbreaking solution: a framework centered around Represented Markov Decision Processes (r-MDPs). This pioneering framework, currently under review, is engineered to craft a concise set of tailored policies expressly designed for a specific user cohort. Its ultimate goal? To streamline the labyrinthine regulatory review process while preserving the essence of personalization. Within an r-MDP, individuals boasting unique preferences are thoughtfully matched with a compact array of representative policies, meticulously optimized to maximize overall societal well-being. This innovative approach effectively mitigates the formidable challenge posed by prolonged approval procedures by drastically reducing the number of policies that necessitate scrutiny and authorization.
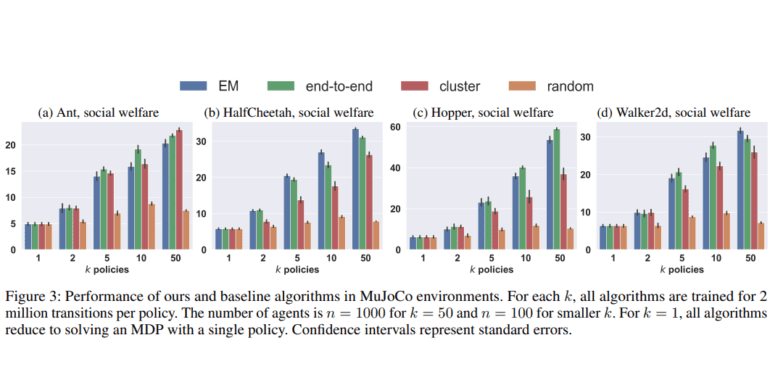
At the core of r-MDPs lies a methodology underpinned by two deep reinforcement learning algorithms, taking inspiration from the tried-and-true principles of classic K-means clustering. These algorithms dissect the challenge into two manageable sub-problems: the optimization of policies for predefined assignments and the optimization of assignments for a set of policies. Empirical investigations conducted in various simulated environments demonstrate the efficacy of these algorithms, showcasing their remarkable ability to foster meaningful personalization while operating within the confines of a limited policy budget.
The performance of this cutting-edge method is particularly laudable for its capacity to achieve substantial personalization with a constrained number of policies. Demonstrating remarkable scalability and efficiency, the algorithms seamlessly adapt to larger policy budgets and diverse environments. In simulated scenarios like resource gathering and robot control tasks, these algorithms have consistently outperformed existing baselines, offering a promising glimpse into their real-world potential. The empirical results underscore the qualitative superiority of this groundbreaking approach, emphasizing its unique ability to learn assignments that directly optimize societal well-being – a stark departure from the heuristic methods entrenched in the existing literature.
Conclusion:
Technion’s innovation with Represented Markov Decision Processes marks a significant step towards enabling personalized machine learning solutions within the confines of regulatory compliance. This breakthrough has the potential to revolutionize various industries, offering safer and more effective personalized experiences for users while navigating the intricate landscape of regulatory approvals. It opens up new opportunities for businesses to deliver highly tailored solutions in sectors where safety and efficacy are paramount.