
TL;DR:
- Representation learning is crucial for drug discovery and understanding biological systems.
- Existing methods often fail to capture the complex relationship between chemical structure and biological characteristics.
- Multimodal contrastive learning, like InfoCORE, bridges this gap by mapping chemical structures to cell microscope images.
- High-throughput drug screening relies on gene expression and cell imaging but faces challenges due to batch effects.
- MIT’s InfoCORE effectively manages batch effects and improves molecular representations, leading to superior performance in drug screening.
- InfoCORE’s adaptability makes it a valuable tool for addressing broader data distribution and fairness issues.
Main AI News:
In the ever-evolving landscape of drug discovery and biotechnology, representation learning has emerged as a pivotal element. Recent studies highlight its crucial role in unraveling the mysteries of drug mechanisms, predicting drug toxicity, and identifying chemical compounds associated with various disease states. However, a significant challenge persists – bridging the gap between a molecule’s chemical structure and its physical or biological attributes.
Many existing molecular representation learning techniques focus solely on encoding a molecule’s chemical identity, resulting in unimodal representations. This approach has limitations, as molecules with similar structures can exhibit vastly different functions in a biological context.
Enter the era of multimodal contrastive learning, a cutting-edge approach that strives to map 2D chemical structures to high-content cell microscope images. High-throughput drug screening, a cornerstone of biotechnology, plays a pivotal role in deciphering the intricate relationship between a drug’s chemical makeup and its biological effects. This method utilizes gene expression data and cell imaging to assess drug impacts.
However, a formidable obstacle looms large: batch effects. Managing batch effects during large-scale screenings necessitates their division into numerous trials, potentially introducing systematic errors and non-biological connections into the data. These batch effects can hinder the accurate interpretation of results, posing a substantial challenge.
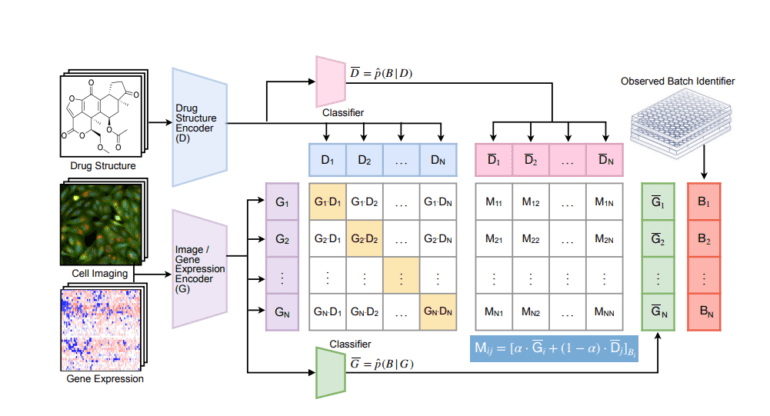
To combat this challenge head-on, a team of diligent researchers has unveiled InfoCORE, short for Information maximization strategy for COnfounder REmoval. The primary objectives of InfoCORE are twofold: effective batch effect management and the enhancement of molecular representations derived from high-throughput drug screening data. Operating under the banner of information maximization, this method places a variational lower bound on the conditional mutual information of latent representations. It achieves this by dynamically reweighting samples to equalize their inferred batch distribution.
In rigorous testing using drug screening data, InfoCORE has outshone its counterparts, showcasing superior performance across a spectrum of tasks, including molecule-phenotype retrieval and chemical property prediction. This impressive feat underscores InfoCORE’s prowess in mitigating the influence of batch effects, resulting in heightened performance levels in molecular analysis and drug discovery endeavors.
Moreover, InfoCORE’s flexibility emerges as a standout feature, capable of tackling complex challenges with finesse. It adeptly manages shifts in the general data distribution and addresses data fairness issues by diminishing correlations with spurious attributes and eliminating sensitive characteristics. Beyond its batch effect eradication capabilities, InfoCORE proves to be a formidable ally in navigating the intricate terrain of data distribution and fairness, making it an indispensable tool for a myriad of challenges in the realm of drug screening and beyond.
Conclusion:
The introduction of InfoCORE signifies a significant advancement in high-throughput drug screening, offering more accurate and reliable results by mitigating the impact of batch effects. This innovation holds promise for pharmaceutical companies, biotech firms, and researchers, enhancing their ability to identify potential drug candidates and accelerate the drug discovery process. Moreover, InfoCORE’s adaptability positions it as a valuable asset in addressing various data-related challenges, making it a game-changer in the evolving landscape of biotechnology and data analysis.