
TL;DR:
- Fireworks AI introduces FireAttention, a custom CUDA kernel optimized for Multi-Query Attention Models like Mixtral.
- Mixtral, an open-source MoE model hosted on Fireworks AI’s platform, outperforms GPT-3.5 on standard benchmarks.
- FireAttention, based on FP16 and FP8, delivers a four-fold speed-up compared to other open-source software.
- Quantization methods like SmoothQuant and AWQ fall short due to non-uniform LLM activation distribution, while FP8 handles it effectively.
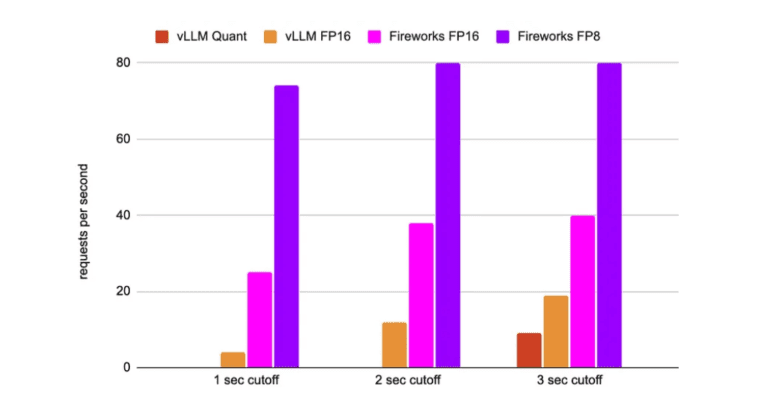
- Researchers evaluate Fireworks FP16 and FP8 Mixtral implementations, showing superior results over vLLM, reducing the model size by half, and improving requests/second.
- The market competition sees tailored solutions like FireAttention as essential for diverse Large Language Model setups.
Main AI News:
In the realm of cutting-edge architecture, the Mixture-of-Experts (MoE) stands as a formidable approach, adhering to the “divide and conquer” principle to tackle intricate tasks. This avant-garde architectural design leverages multiple individual machine learning (ML) models, aptly referred to as experts, each functioning autonomously within their specialized domains, all in pursuit of delivering the most optimal outcomes. To illuminate the versatility of MoE models, Mistral AI recently unveiled Mixtral, an open-source MoE model that has consistently outshone GPT-3.5 across a spectrum of standard benchmarks. Notably, Mixtral found its inaugural home on the illustrious platform of Fireworks AI.
Despite the platform’s commendable accomplishment of achieving an impressive inference speed, clocking in at a remarkable 175 tokens per second, the relentless researchers at Fireworks AI have embarked on a mission to further enhance the efficiency of serving MoE models without compromising their inherent quality. Enter the innovative Large Language Model (LLM) serving stack, boasting the prowess of FP16 and FP8-based FireAttention—a custom CUDA kernel meticulously optimized for Multi-Query Attention Models like Mixtral and tailored to accommodate FP16 and FP8 hardware support.
The pursuit of model enhancement led to the exploration of quantization methods such as SmoothQuant and AWQ. However, these methods fell short, particularly when it came to improving model performance during generation. The primary impediment lay in the non-uniform distribution of LLM activations, a challenge that integer-based methods found daunting. In stark contrast, the utilization of FP8 harnesses the robust support of hardware, rendering it a flexible and adept choice for addressing such intricate distributions.
To evaluate the efficacy of their innovations, the researchers adopted a comprehensive approach. They established a benchmark scenario with a prompt length of 1,000 tokens and a generation target of 50 tokens, encompassing both lengthy prompts and concise generation tasks. Their rigorous quality and performance assessment centered on the Mixtral model, with a particular focus on language comprehension, gauged using the MMLU metric. The MMLU metric, bolstered by an ample corpus of test data examples, served as an effective tool for detecting any potential quantization errors.
For the assessment of latency and throughput, two pivotal metrics came into play: token generation latency for a specified number of requests per second (RPS) and total request latency for a given RPS. The results conclusively demonstrate that the implementation of Fireworks FP16 Mixtral model outperforms the vLLM counterpart—a high-throughput and memory-efficient inference and serving engine for LLMs. Moreover, the FP8 implementation emerges as a substantial improvement over the already efficient FP16, marked not only by enhanced performance but also a halving of the model’s size, facilitating more streamlined deployment. When coupled with the memory bandwidth and FLOPs speed-ups, it ushers in a notable twofold enhancement in effective requests per second.
Conclusion:
Fireworks AI’s FireAttention represents a significant leap in optimizing Multi-Query Attention Models, enabling faster and more efficient large language model serving. This innovation is poised to enhance the market for large language models by addressing specific challenges, ultimately driving improved performance and efficiency in various applications and industries.