
TL;DR:
- Uncertainty estimation is crucial in semantic segmentation in machine learning.
- The ValUES framework addresses the gap between theoretical developments and practical applications.
- It provides a controlled environment to study data ambiguities and method components.
- Empirical findings reveal challenges in separating uncertainty types in real-world scenarios.
- Aggregating scores is a crucial yet often overlooked aspect of uncertainty methods.
- Ensembles and test-time augmentation emerge as robust strategies.
- ValUES dissects uncertainty method components for a deeper understanding.
- The effectiveness of separating different uncertainty types varies with dataset ambiguities.
- The selection of uncertainty methods should be based on dataset properties and application needs.
Main AI News:
In the dynamic realm of machine learning, with a particular focus on semantic segmentation, the precise assessment and validation of uncertainty have risen to paramount significance. Despite numerous studies touting advancements in uncertainty methodologies, there persists a disconnect between theoretical progress and its practical implementation. Pivotal questions persist, such as the feasibility of distinguishing data-related (aleatoric) and model-related (epistemic) uncertainty in real-world scenarios and the identification of critical components pivotal for optimal uncertainty methodology performance.
This study’s primary focal point revolves around the efficacious application of uncertainty methodologies in the domain of segmentation. The challenge arises from the inherent ambiguities surrounding the separation of aleatoric and epistemic uncertainty. While theoretical investigations frequently assert the specific types of uncertainty captured by particular methods, these assertions often lack rigorous empirical substantiation. It becomes imperative to bridge this gap between theory and practice to foster consistency within the field.
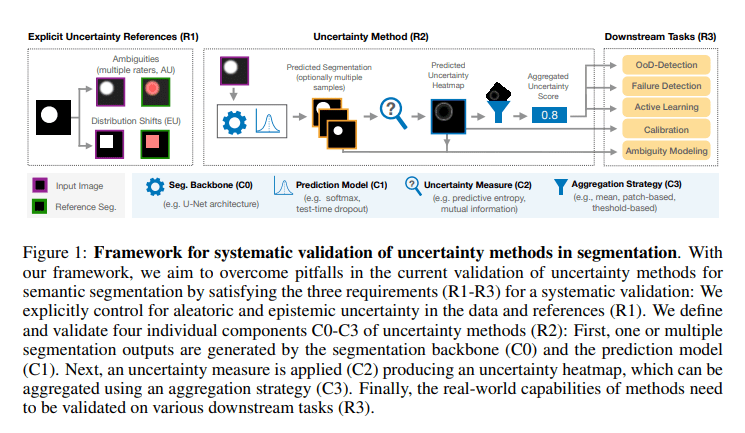
Enter the ValUES framework, meticulously developed by researchers at the German Cancer Research Center. ValUES is designed to address these gaps head-on. Its primary mission is to provide a meticulously controlled environment for the investigation of data ambiguities and distribution shifts, enabling systematic removals of pertinent method components. Furthermore, ValUES establishes an ideal testing ground for the most prevalent applications of uncertainty, such as Out-of-Distribution (OoD) detection, active learning, failure detection, calibration, and ambiguity modeling. In essence, this framework is engineered to surmount the shortcomings of prevailing validation practices for uncertainty methodologies within the realm of semantic segmentation.
The empirical exploration utilizing ValUES has unveiled several pivotal revelations. It has been observed that the segregation of uncertainty types is attainable within simulated environments, but this translation to real-world data is not always seamless. Additionally, the study underscores the underappreciated significance of aggregating scores within uncertainty methodologies. Ensembles have proven to be the most resilient across a diverse array of tasks and settings, with test-time augmentation emerging as a viable, lightweight alternative.
This systematic approach meticulously dissects the constituents of uncertainty methodologies, delving into facets such as the segmentation backbone, prediction models, uncertainty metrics, and aggregation tactics. This comprehensive analysis yields a profound comprehension of the role and interdependencies of each component, elucidating the key drivers behind improvements in uncertainty estimation.
While aleatoric uncertainty measures exhibit superior ambiguity capture in simulated data, this supremacy does not consistently extend to real-world datasets. The study further elucidates that the efficacy of distinguishing epistemic from aleatoric uncertainty is heavily contingent on the inherent ambiguities within the training and test data. The evaluation of downstream tasks, including OoD detection, active learning, and failure detection, furnishes pragmatic insights, aiding in the selection of the most suitable uncertainty methodology tailored to specific application requisites.
Conclusion:
This research underscores that the feasibility and advantages of distinguishing various forms of uncertainty should not be presumed but instead necessitate empirical validation. The study emphasizes the criticality of selecting optimal uncertainty methodology components based on dataset characteristics and the intricate interplay among these constituents. In essence, it charts a course for a more pragmatic and empirically grounded approach to uncertainty estimation in the realm of semantic segmentation.