
TL;DR:
- Speculative Decoding introduces a groundbreaking approach to accelerate Large Language Model (LLM) inference.
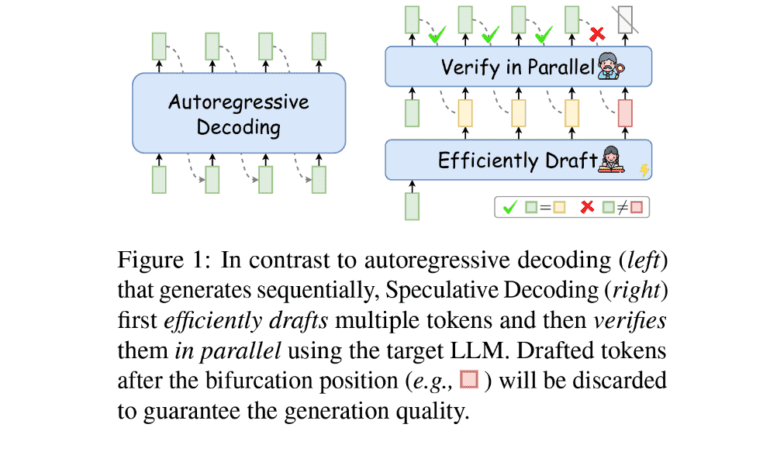
- It consists of two phases: drafting and verification, allowing for simultaneous token processing.
- The drafter model predicts multiple future tokens swiftly, enhancing overall inference speed.
- Parallel verification reduces dependency on sequential processing, minimizing memory read/write operations.
- Speculative Decoding significantly speeds up text generation without compromising quality.
- It is particularly beneficial for real-time AI applications like conversational AI.
- Expands the practicality and accessibility of LLMs for various tasks, including data analysis and language understanding.
Main AI News:
In the realm of natural language processing, Large Language Models (LLMs) reign supreme, serving as the linchpin for a multitude of applications, from language translation to conversational AI. However, a formidable obstacle looms large in the path of these models – inference latency. This latency, an inevitable byproduct of the traditional autoregressive decoding method, where tokens are generated one after the other, becomes more pronounced as the complexity and scale of the model increase, casting a shadow over real-time responsiveness.
Enter Speculative Decoding, a groundbreaking approach that forms the focal point of our investigation. This innovative method diverges from the conventional sequential token generation by ushering in a new era of simultaneous token processing, ushering in an era of unprecedented speed and efficiency in inference. Speculative Decoding comprises two pivotal phases: drafting and verification.
In the drafting phase, a specialized model, aptly named the ‘drafter,’ rapidly foresees multiple future tokens. These tokens, however, are not the final output but rather hypotheses of what the subsequent tokens could be. The drafter model operates with remarkable efficiency, swiftly generating these predictions, a key factor in the overall acceleration of the inference process.
Following the drafting phase, the verification step takes center stage. Here, the target LLM assesses the drafted tokens in parallel, ensuring that the output adheres to the expected quality and coherence standards set by the model. This parallel processing paradigm stands in stark contrast to the conventional approach, where each token’s generation hinges on the preceding ones. By reducing the reliance on sequential processing, Speculative Decoding slashes the time-consuming memory read/write operations that typically burden LLMs.
The outcomes and performance metrics of Speculative Decoding have left a lasting impression. Researchers have demonstrated that this methodology can yield substantial speed boosts in generating text outputs without any compromise in quality. This efficiency gain is particularly noteworthy in the context of the burgeoning demand for real-time, interactive AI applications, where response time is the defining factor. In arenas like conversational AI, where immediacy is paramount for a superior user experience, the reduced latency offered by Speculative Decoding has the potential to be a game-changer.
Beyond its immediate impact, Speculative Decoding has far-reaching implications for the field of AI and machine learning. Providing a more streamlined approach to processing large language models opens up a cornucopia of opportunities for their application, rendering them more accessible and pragmatic across a diverse spectrum of uses. This encompasses real-time interactions and intricate tasks such as large-scale data analysis and language comprehension, where processing speed often proves to be the bottleneck.
Speculative Decoding, undeniably, represents a monumental stride in the realm of LLMs. Its ability to confront the vexing issue of inference latency elevates the practicality of these models and expands their horizons, fostering an environment where responsive and sophisticated AI-driven solutions can flourish. In the ever-evolving landscape of AI innovation, Speculative Decoding stands as a testament to our relentless pursuit of excellence.
Conclusion:
Speculative Decoding is a game-changer for the market, offering a solution to the critical challenge of inference latency in Large Language Models. This innovation paves the way for more responsive and efficient AI-driven solutions, expanding the potential applications across various industries, ultimately enhancing the market’s competitiveness and adaptability to real-time demands.