
TL;DR:
- COPlanner is a groundbreaking framework for model-based reinforcement learning (MBRL).
- MBRL faces challenges in managing imperfect dynamic models in complex environments.
- Recent research explores strategies like Plan to Predict (P2P) and Model-Ensemble Exploration and Exploitation (MEEE) to tackle model inaccuracies.
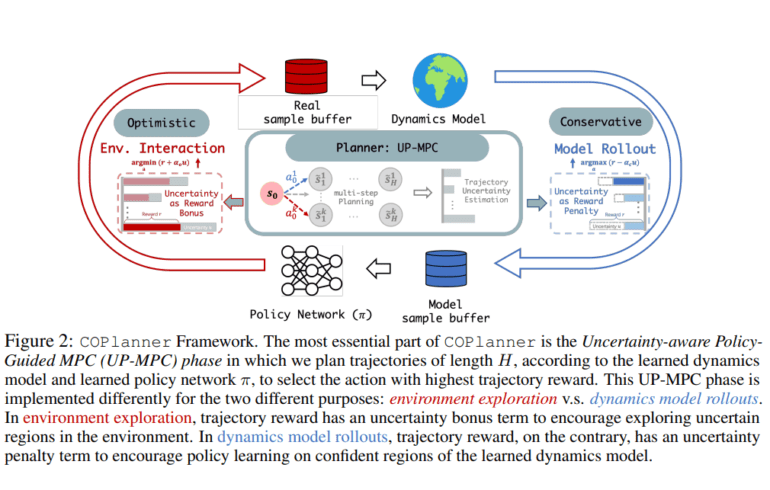
- COPlanner, developed in collaboration with JPMorgan AI Research and Shanghai Qi Zhi Institute, introduces UP-MPC, an uncertainty-aware policy-guided model predictive control.
- COPlanner’s comparative analysis demonstrates significant performance enhancements over existing methods, especially in challenging visual tasks.
- The study showcases COPlanner’s improved sample efficiency and asymptotic performance in various control tasks.
- COPlanner’s hyperparameter ablation results offer valuable insights.
Main AI News:
In the realm of model-based reinforcement learning (MBRL), managing the imperfections of dynamic models has long been a daunting challenge. These imperfections are especially pronounced in complex environments, where the ability to accurately forecast models becomes a critical factor for optimal policy learning. Overcoming this challenge necessitates innovation in MBRL methodologies that can effectively compensate for these model inaccuracies.
Recent advancements in MBRL research have explored various strategies to address dynamic model inaccuracies. Among them, the “Plan to Predict” (P2P) approach focuses on developing uncertainty-anticipating models to steer clear of uncertain regions during rollouts. “Branched and bidirectional rollouts” adopt shorter horizons to mitigate early-stage model errors, albeit at the potential cost of limiting planning capabilities. A notable breakthrough comes from the “Model-Ensemble Exploration and Exploitation” (MEEE) method, which expands the dynamics model while minimizing error impacts during rollouts through the shrewd utilization of uncertainty in loss calculation.
In collaboration with JPMorgan AI Research and the Shanghai Qi Zhi Institute, researchers from the University of Maryland and Tsinghua University have introduced a game-changing innovation within the MBRL paradigm: COPlanner. This revolutionary framework leverages an uncertainty-aware policy-guided model predictive control (UP-MPC) as its cornerstone. The UP-MPC component plays a pivotal role in estimating uncertainties and selecting optimal actions. Furthermore, the research includes a meticulous ablation study conducted on the Hopper-hop task within the visual control domain of DMC, with a particular emphasis on various uncertainty estimation methods and their computational time requirements.
A standout feature of COPlanner is its rigorous comparative analysis with existing MBRL methods. The research presents visual trajectories derived from real environment evaluations, shedding light on the performance disparities between DreamerV3 and COPlanner-DreamerV3. Specifically, it dissects tasks such as Hopper-hop and Quadruped-walk, offering a compelling visual representation of COPlanner’s remarkable improvements over conventional approaches. This visual evidence underscores COPlanner’s prowess in tackling tasks of varying complexities, solidifying its position as a practical and innovative solution in the realm of model-based reinforcement learning.
The study’s findings unequivocally demonstrate COPlanner’s significant enhancements in sample efficiency and asymptotic performance, particularly in proprioceptive and visual continuous control tasks. Notably, COPlanner excels in challenging visual tasks, where its optimistic exploration and conservative rollouts yield the most promising results. The research also provides valuable insights into how model prediction error and rollout uncertainty evolve as the environment steps to progress. Moreover, it delves into the ablation results for various hyperparameters of COPlanner, including the optimistic rate, conservative rate, action candidate number, and planning horizon.
Conclusion:
COPlanner emerges as a game-changing breakthrough in the realm of model-based reinforcement learning, offering a transformative approach to address dynamic model inaccuracies and significantly enhance the efficiency and performance of autonomous agents in complex and unpredictable environments. This pioneering research collaboration promises to reshape the future landscape of AI-driven decision-making and robotics.