
TL;DR:
- Traditional neural networks like RNNs garnered attention before ChatGPT.
- RWKV, a novel RNN with GPT-level performance, requires 10x-100x less compute power.
- Transformers, including ChatGPT, have memory and compute limitations.
- RWKV combines parallelizable training with RNN efficiency.
- It offers lower resource usage, linear scalability, and multilingual capabilities.
- Challenges include prompt formatting and tasks requiring look-back.
- RWKV operates as a sponsor-supported non-profit under the Linux Foundation.
- It eliminates the need for hundreds of GPUs in model training.
- A pre-trained 7B world model is available on HuggingFace.
Main AI News:
Before the market turned its focus toward GenAI, particularly ChatGPT, traditional neural networks like Recurrent Neural Networks (RNNs) held the spotlight. These RNNs, with their “short-term” memory capabilities, continue to power smart technologies such as Apple’s Siri and Google Translate, proving their relevance in the field.
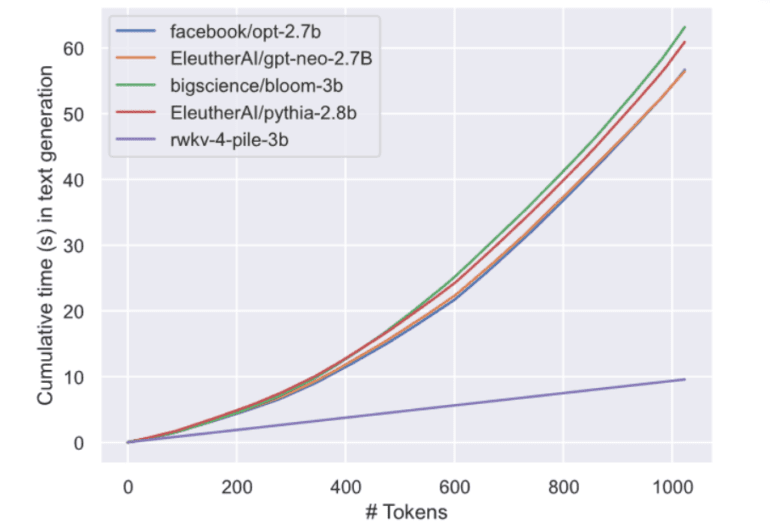
However, a recent groundbreaking paper titled “RWKV: Reinventing RNNs for the Transformer Era” has introduced an RNN with GPT-level Language Model (LLM) performance. What’s even more astonishing is that this RNN can be trained in a parallelizable manner with a compute requirement 10x to 100x lower than that of traditional transformers, meaning fewer GPUs are needed.
This innovative paper delves into how transformers like ChatGPT have revolutionized the world of natural language processing (NLP) but grapple with memory and computational complexities that scale quadratically with sequence length. On the other hand, RNNs exhibit linear scaling in memory and computational requirements, making them more resource-efficient. However, RNNs face limitations in parallelization and scalability, hindering their ability to match the performance of transformers. The solution presented in the paper is the Receptance Weighted Key Value (RWKV) model architecture, which combines the efficient parallelizable training of transformers with the resource efficiency of RNNs.
The initial results are nothing short of remarkable. The RWKV approach offers several advantages, including:
- Lower resource usage (VRAM, CPU, GPU, etc.) during both runtime and training.
- A substantial reduction in compute requirements, ranging from 10x to 100x less than transformers with large context sizes.
- Linear scalability to any context length (unlike transformers, which scale quadratically).
- Comparable performance in terms of answer quality and capability.
- Enhanced training in various languages, surpassing most existing models, including Chinese and Japanese.
Despite these achievements, RWKV models do face certain challenges, such as sensitivity to prompt formatting and weaker performance in tasks requiring look-back. Adapting prompts accordingly can help mitigate these issues.
It’s worth noting that RWKV (wiki) operates as an open-source, sponsor-supported non-profit initiative under the Linux Foundation. Their mission is to amalgamate the strengths of RNNs and transformer technologies, promising exceptional performance, swift inference, efficient resource usage, unlimited context length, and free sentence embedding. What sets RWKV apart from traditional LLMs is its complete freedom from attention mechanisms.
The implications of projects like RWKV are monumental. Instead of necessitating the acquisition or rental of 100 GPUs for LLM model training, RWKV models can deliver comparable results at a fraction of the cost, requiring fewer than 10 GPUs.
Furthermore, a pre-trained, fine-tuned 7B world model, trained on a diverse mix of data, including samples from over 100 languages, and partially instruction-trained, is readily available on HuggingFace. This opens up exciting possibilities for the AI community and beyond, heralding a new era in AI model development.
Conclusion:
RWKV’s emergence marks a significant shift in AI model efficiency, reducing compute requirements and enhancing multilingual capabilities. This development has the potential to disrupt the market by significantly lowering the cost of high-performance model training, making AI more accessible to a wider range of businesses and developers.