
TL;DR:
- Recent advances in Multi-Modal (MM) pre-training have expanded Machine Learning (ML) models’ capabilities to process text, images, audio, and video.
- MultiModal Large Language Models (MM-LLMs) combine pre-trained unimodal models, like LLMs, with additional modalities for cost-effective and versatile data processing.
- Models such as GPT-4(Vision) and Gemini exemplify MM-LLMs’ ability to comprehend and generate multimodal content.
- Researchers focus on aligning modalities within MM-LLMs for improved human interaction and performance across diverse tasks.
- A collaborative study sheds light on MM-LLMs’ architecture, diversity, and real-world performance, enhancing our understanding of this evolving field.
Main AI News:
In recent times, the realm of Multi-Modal (MM) pre-training has witnessed significant advancements, revolutionizing the capabilities of Machine Learning (ML) models in comprehending and processing diverse data types, spanning text, images, audio, and video. This groundbreaking progress has culminated in the emergence of sophisticated MultiModal Large Language Models (MM-LLMs), marking a pivotal moment in AI research and development.
MM-LLMs represent a fusion of pre-trained unimodal models, primarily Large Language Models (LLMs), with additional modalities strategically integrated to harness their individual strengths. Compared to the resource-intensive task of training multimodal models from scratch, this approach not only reduces computational costs but also amplifies the model’s proficiency in handling a wide spectrum of data types.
The landscape of MM-LLMs boasts exceptional models like GPT-4(Vision) and Gemini, exemplifying their prowess in comprehending and generating multimodal content. These models have set new benchmarks in the field, demonstrating their proficiency in processing not only text but also images, audio, and video. Pioneering models such as Flamingo, BLIP-2, and Kosmos-1 have showcased their ability to process a diverse range of modalities, further emphasizing the potential of MM-LLMs.
However, the seamless integration of LLMs with other modal models remains a critical challenge in the development of MM-LLMs. For these modalities to align with human intentions and comprehension, meticulous tuning and alignment are imperative. Researchers have been dedicated to enhancing the capabilities of conventional LLMs, preserving their innate reasoning and decision-making abilities, and expanding their competence across a broader spectrum of multimodal tasks.
A recent comprehensive study conducted by a collaborative team of researchers from Tencent AI Lab, Kyoto University, and Shenyang Institute of Automation has shed light on the intricate domain of MM-LLMs. This extensive research encompasses the formulation of model architecture and training pipelines, covering a diverse array of topics. The study, at its core, imparts a fundamental understanding of the key principles governing the development of MM-LLMs.
Following the elucidation of design formulations, the study delves into the current state of MM-LLMs. It provides succinct introductions to each of the 26 identified MM-LLMs, accentuating their distinctive compositions and remarkable attributes. This endeavor equips readers with a profound insight into the diversity and nuances of models currently driving advancements within the MM-LLMs domain.
A critical facet of the study involves the rigorous evaluation of MM-LLMs against industry standards. The assessment meticulously evaluates the performance of these models in both controlled environments and real-world scenarios, offering valuable insights into their practical utility. Furthermore, the study consolidates successful training approaches and formulas that have significantly enhanced the overall effectiveness of MM-LLMs.
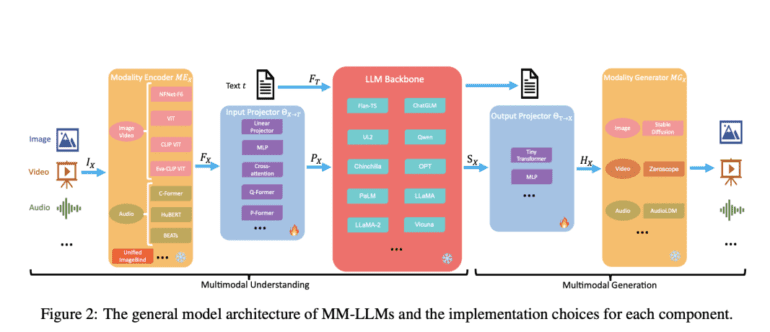
Central to the general model architecture of MultiModal Large Language Models (MM-LLMs) are five key components:
- Modality Encoder: This component translates input data from various modalities, including text, images, audio, and more, into a format intelligible to the LLM.
- LLM Backbone: Serving as the bedrock of language processing and generation, this element typically comprises a pre-trained model.
- Modality Generator: Essential for models emphasizing multimodal comprehension and generation, this component transforms the LLM’s outputs into diverse modalities.
- Input Projector: A pivotal element facilitating the integration and alignment of encoded multimodal inputs with the LLM backbone, ensuring seamless communication.
- Output Projector: Post-processing the LLM’s output into a suitable format for multimodal expression, enabling comprehensive communication across modalities.
In the dynamic landscape of AI, MM-LLMs stand as a testament to the relentless pursuit of innovation and the evolving landscape of language models, promising transformative applications across industries. As research continues to push the boundaries of MM-LLMs, the future holds exciting prospects for businesses and AI enthusiasts alike.
Conclusion:
The emergence of MultiModal Large Language Models (MM-LLMs) presents a promising frontier for businesses across various industries. These models offer cost-effective solutions for processing diverse data types, allowing companies to harness the power of AI in multimodal content generation and comprehension. As MM-LLMs continue to evolve and align with human intent, businesses can anticipate transformative applications that enhance their competitiveness and innovation in the market.