
TL;DR:
- Fudan University introduces SpeechGPT-Gen, an 8B-parameter Speech Large Language Model (SLLM).
- Challenges in integrating semantic and perceptual information in traditional methods addressed by SpeechGPT-Gen.
- Chain-of-Information Generation (CoIG) method used for enhanced speech generation.
- Clear separation of semantic and perceptual information modeling improves efficiency.
- Autoregressive model for semantic content and a non-autoregressive model with flow matching for perceptual nuances.
- Impressive results in zero-shot text-to-speech, maintaining low Word Error Rates (WER) and speaker similarity.
- Outperforms traditional methods in zero-shot voice conversion and speech-to-speech dialogue.
- Innovative use of semantic information in flow matching enhances speech quality.
- Scalability ensures effectiveness in various applications.
Main AI News:
In the realm of AI and machine learning, the advent of Large Language Models (LLMs) has ushered in a new era of innovation. These models have proven themselves invaluable in numerous applications, yet a persistent challenge has hindered their full potential: the seamless integration of semantic and perceptual information. This challenge of marrying meaning and perception has given rise to inefficiencies and redundancies within traditional methods. Enter SpeechGPT-Gen, an ingenious breakthrough brought to you by the researchers at Fudan University.
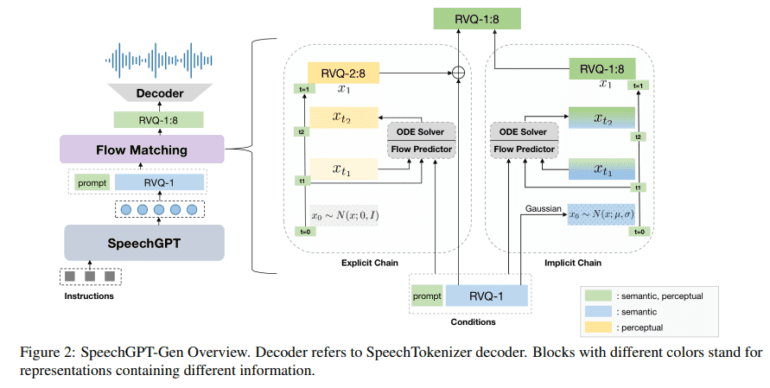
SpeechGPT-Gen, harnessed through the innovative Chain-of-Information Generation (CoIG) technique, heralds a transformative shift in the landscape of speech generation. Conventional approaches often struggle to unite semantic and perceptual information efficiently, akin to attempting to paint a detailed picture with broad, overlapping strokes. In contrast, CoIG operates like a skilled artist using distinct brushes for different elements in a masterpiece, ensuring that every facet of speech – be it semantic or perceptual – receives its due attention.
The methodology behind SpeechGPT-Gen is nothing short of fascinating. It employs an autoregressive model rooted in LLMs for semantic information modeling, dealing with the essence, meaning, and context of speech. Concurrently, a non-autoregressive model employing flow matching is utilized for perceptual information modeling, delving into the subtleties of speech, such as tone, pitch, and rhythm. This clear segregation ushers in a refined and efficient speech processing paradigm, eradicating the redundancies that have long plagued conventional approaches.
In the domain of zero-shot text-to-speech, SpeechGPT-Gen achieves remarkable results, boasting lower Word Error Rates (WER) while preserving speaker individuality. This attests to its sophisticated semantic modeling prowess and its knack for preserving the distinct voices of individuals. In tasks like zero-shot voice conversion and speech-to-speech dialogue, the model continues to shine, surpassing traditional methods in content accuracy and speaker similarity. These accomplishments underscore SpeechGPT-Gen’s practical efficacy in real-world scenarios, marking a significant leap in the field.
A particularly noteworthy feature of SpeechGPT-Gen lies in its utilization of semantic information as a prior in flow matching. This ingenious innovation represents a substantial improvement over standard Gaussian techniques, enhancing the model’s efficiency in transitioning from a basic prior distribution to a complex, real data distribution. This, in turn, not only heightens the accuracy of speech generation but also enriches the naturalness and quality of the synthesized speech.
The scalability of SpeechGPT-Gen is a testament to its excellence. As the model’s size and data processing capabilities expand, it consistently reduces training loss and enhances performance. This scalability proves invaluable, ensuring that the model remains adaptable and efficient as it takes on a broader spectrum of applications and evolving requirements.
Conclusion:
Fudan University’s SpeechGPT-Gen represents a significant advancement in semantic and perceptual information modeling for speech generation. Its innovative approach and remarkable results in diverse applications position it as a game-changer in the market, offering enhanced efficiency and quality in speech generation, with potential applications across industries such as voice assistants, content creation, and customer service automation. This breakthrough paves the way for improved user experiences and greater efficiency in real-world scenarios.