
TL;DR:
- Chinese University of Hong Kong and Tencent AI Lab introduce the Multimodal Pathway Transformer (M2PT).
- M2PT enhances transformers for specific modalities by incorporating seemingly irrelevant data from other modalities.
- The approach outperforms traditional methods, demonstrating substantial performance improvements in image recognition, point cloud analysis, video understanding, and audio recognition.
- M2PT-Point stands out with remarkable enhancements in key metrics compared to baseline models.
- M2PT promises to revolutionize multimodal data processing, transcending the limitations of data pairing and offering transformative possibilities for AI applications.
Main AI News:
The era of transformers has ushered in a new era of technological prowess, transcending traditional boundaries and revolutionizing the landscape of artificial intelligence. Researchers from the Chinese University of Hong Kong and Tencent AI Lab have emerged as trailblazers in this transformative journey, introducing a groundbreaking approach that promises to reshape the very core of multimodal data processing.
Transformers, renowned for their adaptability and efficiency, have penetrated a myriad of applications, from text classification to object detection, map construction to audio spectrogram recognition. Their versatility extends even further into the realm of multimodal tasks, as demonstrated by the phenomenal success of CLIP’s utilization of image-text pairs for unparalleled image recognition capabilities. This underscores transformers’ unparalleled efficacy in establishing a universal sequence-to-sequence modeling framework, enabling the creation of embeddings that harmonize data representation across diverse modalities.
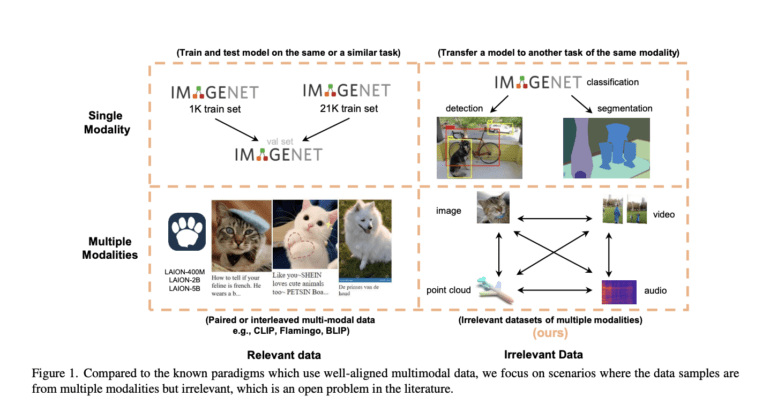
CLIP, a pioneering endeavor, showcases a notable methodology where data from one modality, specifically text, enhances a model’s performance in another, such as images. However, a substantial challenge that often goes unaddressed is the necessity for relevant paired data samples. For example, while training with image-audio pairs could potentially elevate image recognition, the effectiveness of employing a pure audio dataset to enhance ImageNet classification, without meaningful connections between audio and image samples, remains a lingering question.
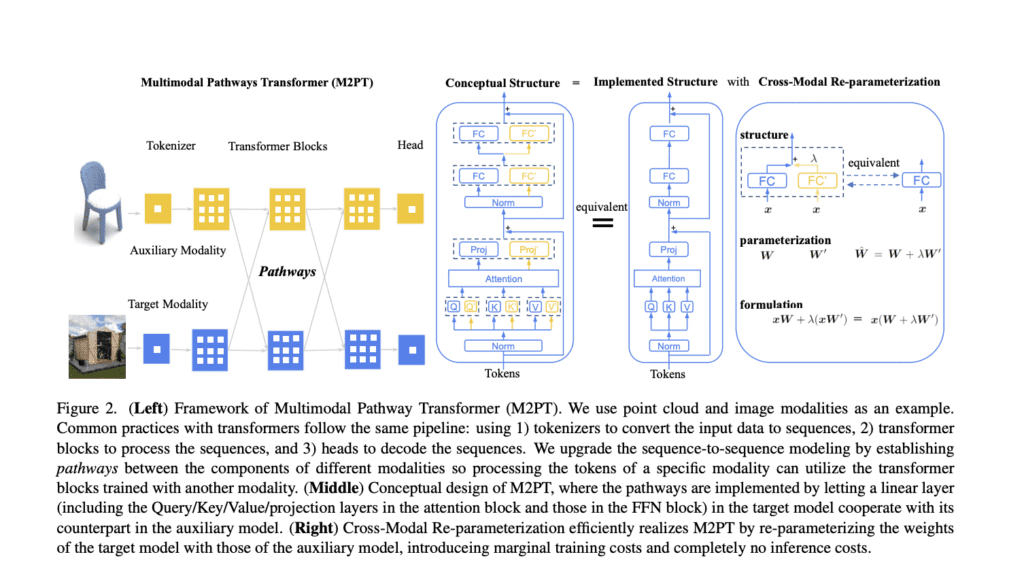
Enter the Multimodal Pathway Transformer (M2PT), an ingenious creation by the researchers at The Chinese University of Hong Kong and Tencent AI Lab. Their approach seeks to elevate transformers tailored for specific modalities, such as ImageNet, by ingeniously incorporating seemingly irrelevant data from unrelated modalities, such as audio or point cloud datasets. What sets M2PT apart from its peers is its ability to transcend the reliance on paired or interleaved data from different modalities. The overarching goal is to demonstrate a marked enhancement in model performance by forging connections between transformers operating in disparate modalities, where the data samples from the target modality are intentionally divergent from those of the auxiliary modalities.
M2PT achieves this synergy by establishing connections between components of a target modality model and an auxiliary model through dedicated pathways. This groundbreaking integration allows for the simultaneous processing of target modality data by both models, harnessing the universal sequence-to-sequence modeling prowess of transformers across two distinct modalities. Key components include modality-specific tokenizers, task-specific heads, and innovative utilization of auxiliary model transformer blocks with cross-module re-parameterization, facilitating the exploitation of additional weights without incurring any inference costs. By strategically incorporating seemingly irrelevant data from other modalities, their method has consistently demonstrated substantial performance improvements across a spectrum of domains, including image recognition, point cloud analysis, video understanding, and audio recognition.
The experimental findings presented by the researchers are nothing short of astounding. In the realm of image recognition, they have employed the ViT-B architecture to compare M2PT-Video, M2PT-Audio, and M2PT-Point against the industry benchmarks SemMAE, MFF, and MAE. The results on prestigious datasets like ImageNet, MS COCO, and ADE20K speak volumes, showcasing unparalleled accuracy and task performance improvements. Notably, M2PT-Point has emerged as the star performer, unveiling substantial enhancements across crucial metrics like APbox, APmask, and mIOU when compared to baseline models.
Source: Marktechpost Media Inc.
Conclusion:
The Multimodal Pathway Transformer (M2PT) is a testament to the ingenuity and forward-thinking approach of the researchers from The Chinese University of Hong Kong and Tencent AI Lab. Their groundbreaking work has paved the way for a new era in multimodal data processing, transcending the limitations of traditional data pairing and offering a promising future where the power of transformers can be harnessed across a multitude of modalities. This innovation not only has the potential to redefine the way we approach artificial intelligence but also holds the promise of transforming industries and applications across the board.