
TL;DR:
- AgentBoard, an innovative evaluation framework, is introduced for analyzing Language Model (LLM) agents.
- Developed collaboratively by prestigious Chinese institutions, AgentBoard addresses the limitations of traditional LLM evaluation methods.
- Key features of AgentBoard include a fine-grained progress rate metric, a comprehensive toolkit for interactive visualization, and testing in diverse tasks and environments.
- It emphasizes multi-round interactions and partially observable settings, mirroring real-world challenges.
- AgentBoard’s research explores the multifaceted capabilities of LLMs, including emergent reasoning, instruction-following skills, and specialized training methods.
- Dimensions evaluated encompass grounding goals, world modeling, step-by-step planning, and self-reflection.
Main AI News:
The advancement of Language Model (LLM) technology has brought about a paradigm shift in various industries, from natural language understanding to AI-driven applications. Ensuring the seamless integration of LLMs into practical scenarios requires a robust evaluation framework that can effectively benchmark their performance. However, traditional evaluation methods fall short when dealing with the complexity of multi-turn interactions, partially observable environments, and diverse real-world scenarios. In this regard, a groundbreaking initiative has emerged from the collaborative efforts of renowned Chinese institutions including the University of Hong Kong, Zhejiang University, Shanghai Jiao Tong University, Tsinghua University, School of Engineering, Westlake University, and The Hong Kong University of Science and Technology.
Introducing ‘AGENTBOARD’: A Game-Changing Open-Source Evaluation Framework for LLM Agents
The collective ingenuity of these institutions has given rise to ‘AgentBoard,’ an innovative benchmark and open-source evaluation framework designed exclusively for the analysis of LLM agents. AgentBoard is a significant leap forward, addressing the pressing need for a comprehensive evaluation approach that captures the intricacies of multi-round interactions and decision-making in dynamic contexts.
AgentBoard’s Key Features:
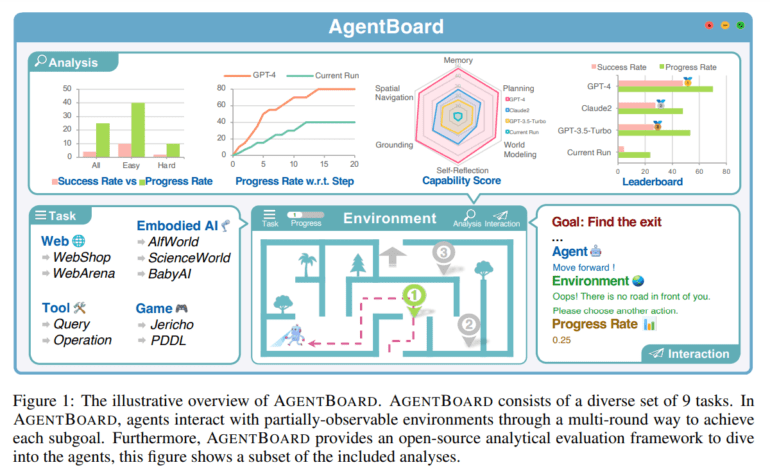
- Fine-Grained Progress Rate Metric: Unlike conventional evaluation frameworks that rely on simplified success rate metrics, AgentBoard introduces a fine-grained progress rate metric. This metric provides a more nuanced understanding of an LLM agent’s capabilities, allowing for a deeper analysis of its performance.
- Comprehensive Toolkit for Interactive Visualization: AgentBoard goes beyond traditional evaluation methods by offering a comprehensive toolkit for interactive visualization. This toolkit sheds light on LLM agents’ strengths and limitations, making it a valuable resource for researchers and developers.
- Diverse Tasks and Environments: With nine diverse tasks and 1013 environments, AgentBoard covers a wide spectrum of challenges, including embodied AI, game agents, web agents, and tool agents. This diversity ensures that LLM agents are tested in a variety of scenarios, enabling a more robust assessment of their capabilities.
- Multi-Round and Partially Observable Characteristics: AgentBoard excels in maintaining partially observable settings and facilitating multi-round interactions. These features mirror real-world situations where LLM agents must make decisions based on evolving information.
Analyzing the Multifaceted Capabilities of LLMs
The research conducted using AgentBoard delves deep into the multifaceted capabilities of LLMs as decision-making agents. While Reinforcement Learning provides general solutions, LLMs shine in decision-making with emergent reasoning and instruction-following skills. Techniques like contextual prompting enable LLMs to generate executable actions, and specialized training methods transform them into adept agents.
Key Dimensions Explored by AgentBoard:
- Grounding Goals
- World Modeling
- Step-by-Step Planning
- Self-Reflection
AgentBoard: Paving the Way for Analytic Evaluation of LLMs
In summary, AgentBoard is a comprehensive benchmark and evaluation framework focusing on LLMs as versatile agents. It employs a fine-grained progress rate metric and a thorough evaluation toolkit for nuanced analysis in text-based environments. By maintaining partially observable settings and ensuring multi-round interactions, AgentBoard facilitates easy assessment through interactive visualization. This benchmark introduces a unified progress rate metric that highlights substantial advancements beyond traditional success rates.
The customizable AgentBoard evaluation framework empowers researchers and developers to conduct detailed analyses of agent abilities, emphasizing the critical role of analytic evaluation in advancing LLM technology. This groundbreaking framework not only benefits established models like GPT-4 but also holds promise for open-weight code LLMs such as DeepSeek LLM and Lemur, ushering in a new era of LLM evaluation and development.
Conclusion:
AgentBoard’s introduction represents a significant advancement in LLM evaluation, with profound implications for the market. It empowers developers and researchers to gain deeper insights into LLM agents’ capabilities, paving the way for more informed decision-making in the integration of LLM technology across industries. This framework fosters the development of more robust LLM models, enhancing their practical applications and potential for market disruption.