
TL;DR:
- Alibaba introduces EE-Tuning for Large Language Models (LLMs), addressing computational challenges during inference.
- EE-Tuning strategically incorporates early exit layers into pre-trained LLMs, reducing the need for full computation and accelerating inference.
- This two-stage process involves initializing and fine-tuning early exit layers while preserving the core parameters of the original model.
- Rigorous experimentation demonstrates EE-Tuning’s efficacy across various model sizes, with significant speedups on downstream tasks while maintaining output quality.
- EE-Tuning revolutionizes LLM tuning, making advanced models more accessible and manageable for the AI community.
Main AI News:
In the realm of artificial intelligence (AI) and natural language processing (NLP), large language models (LLMs) have emerged as a game-changer, capable of comprehending and generating human-like text. However, their computational demands, especially during inference, pose significant challenges. As these models expand in size to boost performance, latency and resource requirements skyrocket.
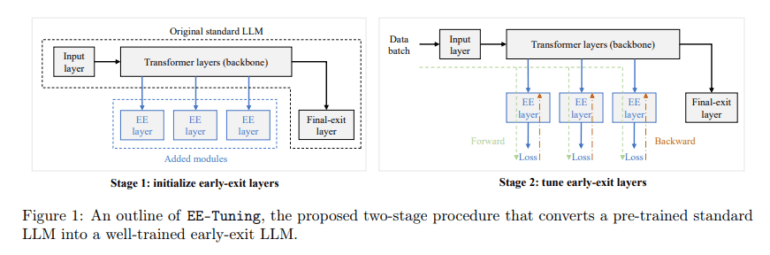
Enter EE-Tuning, a groundbreaking solution introduced by the Alibaba Group, aimed at revolutionizing LLM tuning for superior performance. Unlike traditional methods that involve exhaustive pre-training across all parameters, EE-Tuning takes a different approach. It strategically incorporates early exit layers into pre-trained LLMs, enabling the generation of outputs at intermediate stages, thereby reducing the need for full computation and speeding up inference.
The brilliance of EE-Tuning lies in its ability to fine-tune these additional layers efficiently, ensuring scalability and manageability as models become more complex. This innovative approach involves a two-stage process: initialization of early-exit layers followed by fine-tuning and optimization against selected training losses. By keeping the core parameters of the original model intact, EE-Tuning minimizes computational load while offering flexibility and customization to suit diverse operational needs.
Rigorous experimentation has validated the effectiveness of EE-Tuning across various model sizes, including those boasting up to 70 billion parameters. This novel technique enables large models to swiftly acquire early-exit capabilities, using significantly fewer GPU hours and training data compared to traditional pre-training methods. Importantly, this efficiency does not compromise performance; converted models demonstrate notable speedups on downstream tasks while maintaining, and in some cases enhancing, output quality.
Conclusion:
The introduction of EE-Tuning by Alibaba signifies a significant advancement in the field of artificial intelligence, particularly for large language models. By streamlining tuning processes and enhancing model efficiency, EE-Tuning not only reduces computational demands but also makes advanced LLMs more accessible to the broader market. This innovation has the potential to revolutionize AI applications across industries, driving further advancements and adoption in the market.