
TL;DR:
- McGill University introduces Pythia 70M, enhancing LLM pre-training efficiency via knowledge distillation.
- Pythia 70M replaces attention heads in transformer models with the cost-effective Hyena mechanism.
- Research highlights improved inference speed and performance over traditional pre-training.
- Distillation techniques result in lower perplexity scores, showcasing superior efficiency.
- Hyena-based models demonstrate competitive performance in language tasks compared to attention-based counterparts.
Main AI News:
In the realm of Natural Language Processing (NLP), the ascent of Large Language Models (LLMs) has been nothing short of transformative. With the advent of the transformer architecture, a new epoch in NLP was inaugurated. Although a precise definition of LLMs remains elusive, they are generally recognized as versatile machine learning models adept at multitasking across diverse natural language processing endeavors. This evolution underscores the profound impact of these models on the domain.
LLMs encompass four pivotal functions: natural language understanding, generation, knowledge-intensive tasks, and reasoning. The architectural landscape continues to diversify, embracing varied strategies, from models integrating both encoders and decoders to specialized encoder-only (e.g., BERT) and decoder-only models (e.g., GPT-4). GPT-4’s decoder-centric design excels notably in natural language generation. However, concerns loom over its substantial energy consumption, underscoring the urgency for sustainable AI solutions.
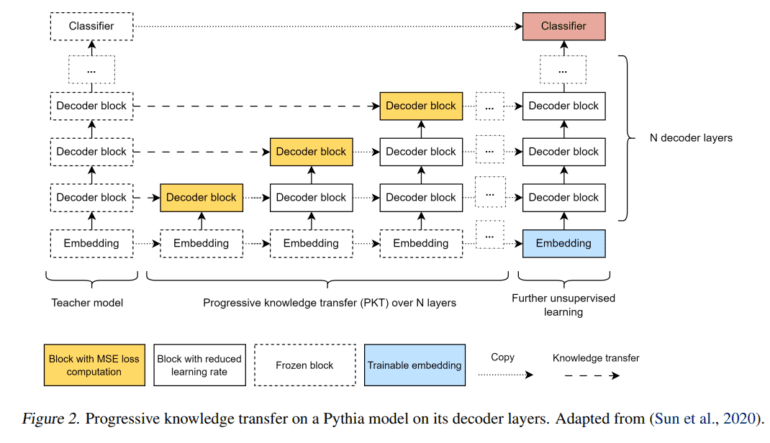
Addressing these concerns, researchers at McGill University have introduced the Pythia 70M model, a groundbreaking approach aimed at optimizing LLM pre-training efficiency through knowledge distillation for inter-architecture transfer. Inspired by the efficient Hyena mechanism, this method replaces attention heads in transformer models with Hyena components, presenting a cost-efficient alternative to conventional pre-training methodologies. This innovation is particularly adept at mitigating the challenges associated with processing extensive contextual information in quadratic attention mechanisms, paving the way for more efficient and scalable LLMs.
Building upon this framework, the researchers leverage the efficient Hyena mechanism to substitute attention heads in transformer models, resulting in notable improvements in inference speed and performance over traditional pre-training methods. This approach squarely tackles the hurdle of processing lengthy contextual information inherent in quadratic attention mechanisms, thereby striving for a harmonious balance between computational prowess and environmental sustainability. The result is a cost-effective and eco-conscious alternative to conventional pre-training techniques.
Quantitative analyses unveil perplexity scores across various models, including Pythia-70M, a pre-trained Hyena model, Hyena student models distilled via Mean Squared Error (MSE) loss, and Hyena student models fine-tuned post-distillation. The pre-trained Hyena model exhibits superior perplexity metrics compared to Pythia-70M, with further enhancements observed post-distillation, culminating in the lowest perplexity scores attained by the fine-tuned Hyena student models. Notably, in language evaluation tasks employing the Language Model Evaluation Harness, Hyena-based models showcase competitive performance across diverse natural language tasks vis-à-vis the attention-based Pythia-70M teacher model.
Conclusion:
McGill University’s Pythia 70M model marks a significant leap forward in optimizing Large Language Models (LLMs), particularly in terms of efficiency and sustainability. By introducing novel techniques like knowledge distillation and leveraging the cost-effective Hyena mechanism, this innovation not only enhances performance but also addresses pressing concerns regarding energy consumption in AI systems. As such, this development signals a promising shift towards more environmentally conscious and economically viable solutions in the NLP market.