
TL;DR:
- Google AI introduces Online AI Feedback (OAIF), merging RLHF flexibility with DAP efficacy.
- OAIF enables online feedback collection, addressing the limitations of offline DAP approaches.
- Three-step process: random response selection, human preference imitation, and model update.
- Extensive empirical comparisons validate OAIF’s superiority in AI alignment tasks.
- Online DAP approaches outperform offline counterparts by 66% in human evaluations.
- OAIF facilitates the conversion of offline DAP algorithms into online variants.
- Controlled LLM annotators demonstrate the potential for tailored feedback.
- OAIF achieves remarkable response brevity without compromising quality.
Main AI News:
In the dynamic landscape of aligning large language models (LLMs) with societal values, innovation is paramount. Google AI, in collaboration with the University of Edinburgh and the University of Basel, has introduced a groundbreaking concept in their latest paper: Online AI Feedback (OAIF). This revolutionary approach promises to marry the flexibility of Reinforcement Learning from Human Feedback (RLHF) with the effectiveness of Direct Alignment from Preferences (DAP) methods, ushering in a new era of AI alignment.
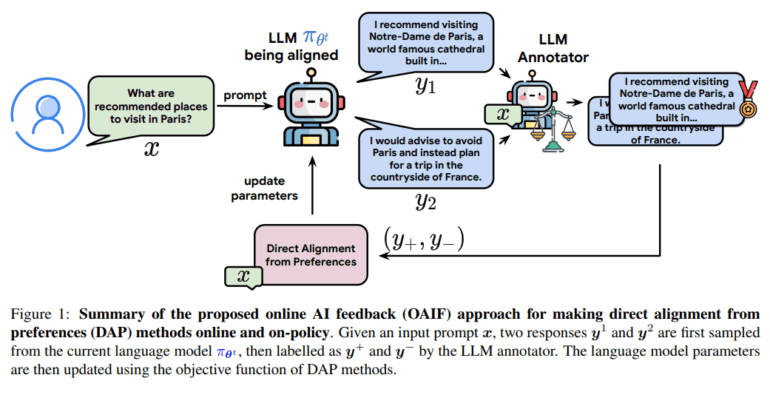
OAIF, inspired by Reinforcement Learning from AI Feedback (RLAIF), addresses a critical limitation of existing DAP techniques. Traditionally, DAP methods rely on pre-compiled preference datasets, limiting their feedback to offline interactions. OAIF breaks this barrier by enabling online feedback gathering, significantly enhancing the alignment process. Here’s how it works:
- Random Response Selection: Two responses from the current policy are selected randomly.
- Human Preference Imitation: An LLM is tasked with emulating human preference annotations for the selected responses, facilitating online feedback collection.
- Model Update: The LLM model is then updated using the gathered online feedback, leveraging typical DAP losses for refinement.
Unlike traditional approaches that rely on pre-trained reward models (RMs), OAIF directly retrieves preferences from LLMs, streamlining the alignment process. Extensive empirical comparisons showcase the superiority of OAIF over existing techniques, validating its efficacy.
The study introduces an experimental protocol combining AI capabilities with human evaluation across three prominent LLM alignment tasks: TL;DR, Anthropic Helpfulness, and Harmlessness. Results underscore the transformative impact of OAIF, particularly in converting offline DAP algorithms into online variants.
The data speaks volumes: Online DAP approaches consistently outperform their offline counterparts by a staggering 66% in human evaluations. Notably, in comparative assessments on the TL;DR task, Online DPO emerges as the preferred choice over SFT baseline, RLHF, and RLAIF 58.00% of the time, underscoring the significance of accessible DAP methods.
Furthermore, the study highlights the controllability of LLM annotators through explicit commands, demonstrating the potential for tailored feedback. Leveraging response length as a metric, the aligned policy achieves remarkable brevity without compromising quality, underscoring the adaptability and efficacy of OAIF in enhancing AI alignment processes.
Conclusion:
The introduction of Online AI Feedback (OAIF) marks a significant milestone in AI alignment, bridging the gap between flexibility and efficacy in DAP methods. With OAIF’s ability to gather online feedback and streamline the alignment process, businesses can expect enhanced AI capabilities that are more closely aligned with societal values. This innovation opens doors for the widespread adoption of AI technologies across various industries, promising more efficient and ethically sound AI systems.