
TL;DR:
- Researchers introduce DiffTOP, leveraging Differentiable Trajectory Optimization for Deep Reinforcement Learning (DRL) and Imitation Learning (IL).
- Different policy depictions significantly impact learning; DiffTOP utilizes high-dimensional sensory data and trajectory optimization for action generation.
- The approach combines deep model-based RL algorithms with differentiable trajectory optimization, optimizing both dynamics and reward models.
- DiffTOP surpasses previous methods in 15 model-based RL tasks and 13 imitation learning tasks, with superior performance in robotic manipulation tasks.
- Compared to alternatives like Energy-Based Models (EBM) and Diffusion, DiffTOP offers enhanced stability and performance in training.
Main AI News:
Recent findings unveil a groundbreaking innovation dubbed ‘DiffTOP’ by researchers at CMU and Peking University. This revolutionary approach harnesses Differentiable Trajectory Optimization (DiffTOP) to steer the actions in Deep Reinforcement Learning (DRL) and Imitation Learning (IL).
As per recent insights, the manner in which a policy is depicted profoundly influences learning efficacy. Diverse policy representations like feed-forward neural networks, energy-based models, and diffusion have been scrutinized in prior studies.
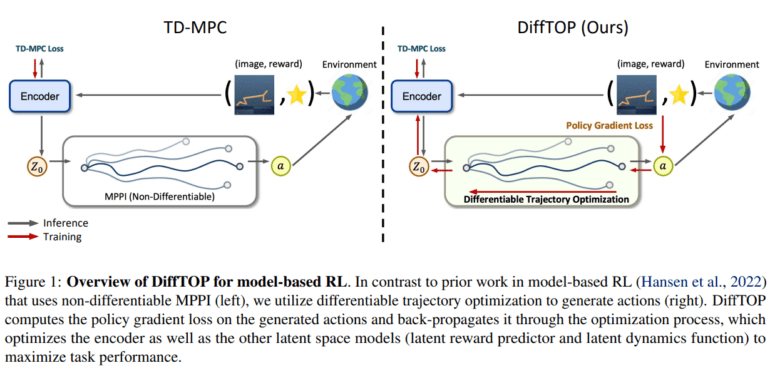
In a recent collaborative effort between Carnegie Mellon University and Peking University, scholars advocate for action generation in deep reinforcement and imitation learning through the lens of high-dimensional sensory data (such as images/point clouds) and differentiable trajectory optimization as the bedrock of policy representation. Traditionally, trajectory optimization relies on a cost function and a dynamics function, a tried and tested control approach. In this paradigm, the policy, defined by neural networks, dictates the parameters governing both the cost function and the dynamics function.
Upon receiving input states—be it pictures, point clouds, or robot joint states—alongside the acquired cost and dynamics functions, the policy endeavors to crack the trajectory optimization puzzle, thereby deciphering the optimal actions to undertake. Crucially, the trajectory optimization can be rendered differentiable, thus ushering in the possibility of back-propagation within the optimization framework. Prior studies have tackled challenges stemming from low-dimensional states in robotics, imitation learning, system identification, and inverse optimal control using differentiable trajectory optimization.
This marks the pioneering showcase of a hybrid methodology amalgamating deep model-based RL algorithms with differentiable trajectory optimization. The team undertakes the onus of mastering the dynamics and cost functions to fine-tune the reward mechanism through computation of the policy gradient loss on the generated actions—a feat made attainable via differentiable trajectory optimization.
However, the crux lies in bridging the chasm between training efficacy and actual control performance. The ‘objective mismatch’ quandary inherent in prevailing model-based RL algorithms necessitates a solution, and herein lies the crux of DiffTOP—Differentiable Trajectory Optimization. By optimizing trajectories, the team endeavors to heighten task proficiency by propagating the policy gradient loss, thereby optimizing both latent dynamics and reward models.
A series of exhaustive experiments serve as a litmus test for DiffTOP, exhibiting its superiority over erstwhile state-of-the-art methodologies across a spectrum of 15 model-based RL tasks and 13 imitation learning tasks. These evaluations are grounded in standardized benchmarking utilizing high-dimensional sensory observations. Among these tasks are 5 Robomimic challenges utilizing image inputs, along with 9 Maniskill1 and Maniskill2 trials deploying point clouds as inputs.
Furthermore, the team conducts a comparative analysis juxtaposing their methodology against feed-forward policy classes, Energy-Based Models (EBM), and Diffusion. Particularly in imitation learning on commonplace robotic manipulation tasks employing high-dimensional sensory data, DiffTOP shines. Compared to the EBM approach, which grapples with training instability due to the exigency of sampling high-quality negative samples, the training regime underpinned by differentiable trajectory optimization unveils superior performance. The proposed modus operandi of learning and optimizing a cost function during testing stages catapults DiffTOP beyond diffusion-based alternatives.
Conclusion:
The introduction of DiffTOP marks a significant advancement in the fields of Deep Reinforcement Learning and Imitation Learning. Its ability to optimize both dynamics and reward models using differentiable trajectory optimization heralds a new era of stability and performance in training. This innovation has the potential to reshape the landscape of the market by offering more robust solutions for tasks ranging from robotics to system identification, enhancing efficiency and efficacy across various industries.