
TL;DR:
- Premier-TACO introduces a novel pretraining framework for few-shot policy learning in machine learning.
- It addresses challenges like Data Distribution Shift, Task Heterogeneity, and Data Quality and Supervision.
- The methodology utilizes a reward-free, dynamics-driven approach for universal and transferable encoder creation.
- Premier-TACO significantly enhances temporal action contrastive learning, enabling large-scale multitask offline pretraining.
- Empirical evaluations across various domains demonstrate substantial performance improvements compared to baseline methods.
- Pre-trained representations exhibit remarkable adaptability to novel tasks and embodiments.
- Fine-tuning experiments showcase versatility, enhancing performance across different domains.
Main AI News:
In the ever-changing landscape of technology, the importance of sequential decision-making (SDM) within machine learning remains paramount. Unlike static tasks, SDM encapsulates the dynamic nature of real-world scenarios, ranging from intricate robotic operations to evolving healthcare protocols. Similar to how foundational models such as BERT and GPT have revolutionized natural language processing by harnessing extensive textual data, pre-trained foundational models hold immense potential for SDM. These models, equipped with a nuanced understanding of decision sequences, possess the capability to tailor themselves to specific tasks, mirroring the adaptability of language models to linguistic subtleties.
However, SDM presents unique hurdles, distinct from prevailing pretraining approaches in vision and language:
- Data Distribution Shift: The challenge arises when training data showcases diverse distributions across different phases, impacting overall performance.
- Task Heterogeneity: Developing universally applicable representations becomes complex due to the varied configurations of tasks.
- Data Quality and Supervision: Scarce availability of high-quality data and expert guidance poses significant challenges in real-world settings.
To tackle these challenges head-on, this article introduces Premier-TACO, a groundbreaking methodology aimed at crafting a versatile and transferable encoder using a reward-free, dynamics-driven, temporal contrastive pretraining objective. By omitting reward signals during pretraining, the model attains the flexibility to generalize effectively across a spectrum of downstream tasks. Employing a world-model approach ensures that the encoder acquires compact representations adaptable to diverse scenarios.
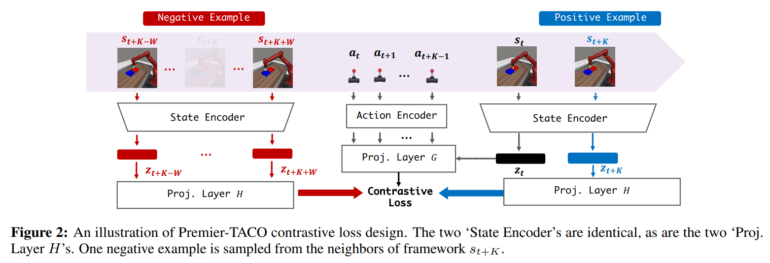
Premier-TACO significantly amplifies the temporal action contrastive learning (TACO) objective (detailed in Figure 3), extending its capabilities to encompass large-scale multitask offline pretraining. Particularly noteworthy is Premier-TACO’s strategic sampling of negative examples, ensuring efficient capture of control-relevant information within the latent representation.
Through empirical assessments conducted across Deepmind Control Suite, MetaWorld, and LIBERO, Premier-TACO showcases remarkable performance enhancement in few-shot imitation learning when compared to baseline methodologies. Specifically, on Deepmind Control Suite, Premier-TACO achieves a staggering relative performance boost of 101%, while on MetaWorld, it records a remarkable 74% improvement, demonstrating resilience even in scenarios with low-quality data.
Moreover, Premier-TACO’s pre-trained representations exhibit exceptional adaptability to novel tasks and embodiments, as evidenced by their performance across various locomotion and robotic manipulation tasks. Even when confronted with unfamiliar camera perspectives or suboptimal data quality, Premier-TACO maintains a significant edge over conventional methods.
Lastly, the versatility of the approach shines through in fine-tuning experiments, where it enhances the performance of large pretrained models like R3M, effectively bridging domain disparities and showcasing robust generalization capabilities.
Conclusion:
The introduction of Premier-TACO marks a significant advancement in the field of few-shot policy learning, offering a robust solution to challenges such as data distribution shifts and task heterogeneity. Its adaptability and performance enhancements indicate promising implications for industries reliant on machine learning applications, potentially revolutionizing how businesses approach decision-making tasks in dynamic environments.