
- META AI introduces MAGNET, a non-autoregressive method for text-conditioned audio generation.
- MAGNET operates on a masked generative sequence modeling technique, reducing inference time and latency.
- The method incorporates a novel rescoring approach using external pre-trained models to enhance audio quality.
- A hybrid version of MAGNET combines autoregressive and non-autoregressive models for optimal efficiency and accuracy.
- Evaluation across text-to-music and text-to-audio tasks shows MAGNET’s results are comparable to autoregressive models with reduced latency.
Main AI News:
In the ever-evolving landscape of AI-driven audio synthesis, META AI has unveiled its groundbreaking innovation: MAGNET. Short for Masked Audio Generation using Non-Autoregressive Transformers, MAGNET represents a paradigm shift in text-conditioned audio generation techniques. Unlike traditional methods that rely on autoregressive models, MAGNET operates non-autoregressively, promising remarkable reductions in inference time and latency.
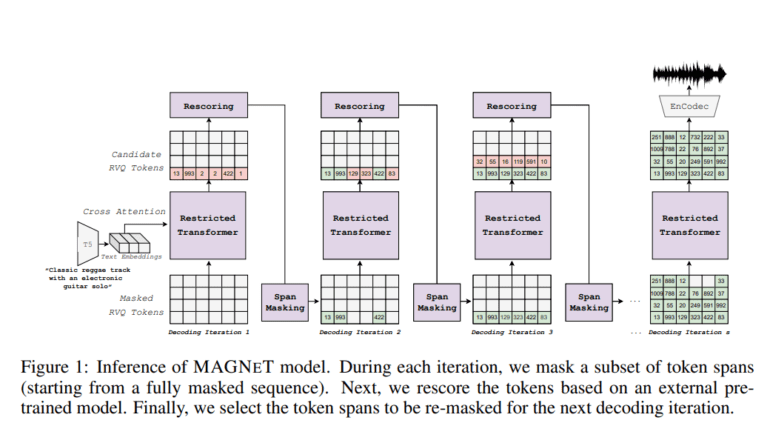
At the heart of MAGNET lies its novel approach to masked generative sequence modeling, which harnesses a multi-stream representation of audio signals. During training, MAGNET dynamically samples a masking rate from a dedicated scheduler, intelligently masking and predicting spans of input tokens conditioned on unmasked ones. This approach enables MAGNET to gradually construct the output audio sequence during inference, utilizing several decoding steps for optimal results.
Complementing its innovative modeling technique, MAGNET introduces a pioneering rescoring method that leverages external pre-trained models to enhance the quality of generated audio. This unique feature sets MAGNET apart, promising superior generation quality compared to conventional methods.
META AI’s research extends further with a hybrid version of MAGNET, which combines elements of both autoregressive and non-autoregressive models. While the initial portion of the token sequence is generated autoregressively, the remainder is decoded in parallel, striking a balance between efficiency and accuracy.
Evaluation of MAGNET across text-to-music and text-to-audio generation tasks demonstrates its efficacy, with results comparable to autoregressive baselines but with significantly reduced latency. META AI’s comprehensive analysis delves into the performance characteristics of both autoregressive and non-autoregressive models, shedding light on the trade-offs involved.
By introducing MAGNET as a pioneering non-autoregressive model for audio generation, META AI paves the way for interactive applications such as music generation and editing within Digital Audio Workstations (DAWs). Moreover, the proposed rescoring method elevates the overall quality of generated audio, reinforcing the practical viability of the approach.
META AI’s groundbreaking work not only advances the field of audio generation but also contributes valuable insights into the effectiveness and applicability of non-autoregressive modeling techniques in real-world scenarios. Through rigorous evaluation and analysis, META AI sets a new standard for efficient and high-quality audio synthesis systems, promising exciting possibilities for future advancements in the field.
Conclusion:
META AI’s introduction of MAGNET represents a significant advancement in text-driven audio synthesis. By pioneering a non-autoregressive approach coupled with innovative rescoring techniques, META AI sets a new standard for efficiency and quality in audio generation. This development opens up exciting possibilities for interactive applications like music generation and editing, signaling a transformative shift in the market towards more efficient and high-quality audio synthesis systems.