
- ResLoRA, an enhanced framework, improves low-rank adaptation (LoRA) for large language models (LLMs).
- It addresses challenges in updating LoRA block weights efficiently due to extensive calculation paths.
- ResLoRA integrates ResNet-inspired blocks and merging approaches for seamless model convergence.
- Experimental results across NLG and NLU domains demonstrate ResLoRA’s superiority over LoRA variants.
- ResLoRA exhibits faster training times and superior image generation quality in text-to-image tasks.
Main AI News:
Recent advancements in large language models (LLMs), characterized by hundreds of billions of parameters, have significantly elevated performance levels across diverse tasks. While fine-tuning LLMs on specific datasets has proven effective in enhancing performance over prompting during inference, the process incurs considerable costs due to the sheer volume of parameters involved. Low-rank adaptation (LoRA) has emerged as a prominent parameter-efficient fine-tuning method for LLMs. However, efficiently updating LoRA block weights remains a challenge owing to the model’s extensive calculation path.
In response to this challenge, several parameter-efficient fine-tuning (PEFT) methods have been proposed. PEFT methods advocate for the freezing of all parameters in the original model, with selective tuning of a limited set of parameters in newly introduced modules. Among these methods, LoRA stands out as one of the most widely used, as it involves freezing the majority of parameters in the original model while updating only a select few in added modules. Notably, LoRA leverages low-rank adaptation, which involves merging matrices in parallel with frozen linear layers during inference. However, the prolonged backward path associated with LoRA presents its own set of challenges, particularly when integrating with complex architectures like ResNet and Transformers, which can impact gradient flow during training.
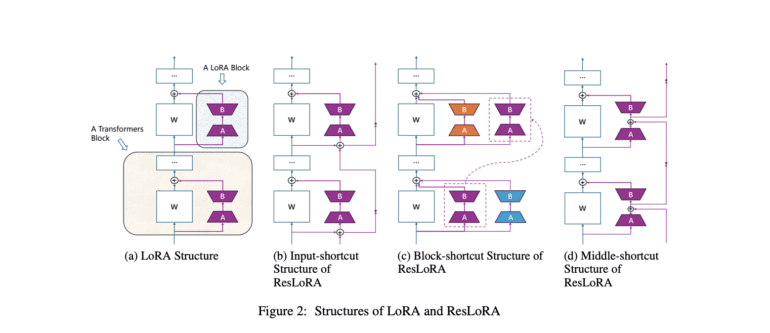
In a collaborative effort between the School of Computer Science and Engineering at Beihang University in Beijing, China, and Microsoft, a novel framework called ResLoRA has been introduced as an enhanced version of LoRA. ResLoRA comprises two main components: ResLoRA blocks and merging approaches. During training, ResLoRA blocks incorporate residual paths into LoRA blocks, while merging approaches facilitate the conversion of ResLoRA to LoRA blocks during inference. Notably, ResLoRA represents the pioneering effort to combine residual paths with LoRA, according to the researchers.
The design of ResLoRA incorporates three blocks inspired by ResNet: input-shortcut, block-shortcut, and middle-shortcut, each integrating residual paths into LoRA blocks. These structural enhancements aim to optimize gradient flow during training and are integral to efficient parameter tuning. However, ResLoRA’s introduction of a non-plain structure contrasts with LoRA’s seamless integration with linear layers, presenting a notable challenge. To mitigate this challenge, a merging approach has been devised. For block-shortcut structures, merging relies on prior block weights, with the precision of scaling factors determined using Frobenius norms to ensure accurate model merging. Two distinct approaches, based on input and block weights, facilitate seamless integration, thereby minimizing latency in inference.
Extensive experiments across natural language generation (NLG) and understanding (NLU) domains have demonstrated the superiority of ResLoRA over LoRA variants such as AdaLoRA, LoHA, and LoKr. ResLoRA and ResLoRAbs consistently outperform LoRA across NLG and NLU benchmarks, showcasing improvements in accuracy ranging from 10.98% to 36.85%. Moreover, ResLoRA exhibits faster training times and superior image generation quality compared to LoRA in text-to-image tasks.
Conclusion:
ResLoRA’s introduction signifies a significant advancement in low-rank adaptation techniques for large language models. Its ability to optimize gradient flow during training and improve parameter efficiency has profound implications for the market, particularly in enhancing model performance across natural language generation and understanding tasks. As ResLoRA continues to outperform existing variants and demonstrate superior training efficiency, it sets a new standard for parameter-efficient fine-tuning methods, likely influencing the trajectory of language model development and application in various industries.