
- UNC-Chapel Hill researchers introduce CRG, enabling VLMs to excel in responding to visual prompts.
- VLMs combine language reasoning with visual encoders but often struggle with fine-grained region understanding.
- CRG is a training-free method that mitigates biases and enhances model performance by focusing on specific image regions.
- It improves visual understanding across various tasks, including spatial reasoning and text-to-image generation.
- CRG’s compatibility with existing models and its robustness make it a practical solution for real-world applications.
Main AI News:
Advancements in large vision-language models (VLMs) hold immense potential in tackling multimodal tasks, amalgamating the reasoning prowess of large language models (LLMs) with visual encoders like ViT. However, while excelling in tasks involving entire images, such as image question answering or description, these models often struggle with fine-grained region grounding, inter-object spatial relations, and compositional reasoning.
This challenge impedes their adeptness in effectively following visual prompts, where cues like bounding boxes aid in directing their focus to pivotal regions. Enhancing the capability of models to follow visual prompts bears the promise of ameliorating performance across diverse visual-language realms, spanning spatial reasoning to referring expression comprehension.
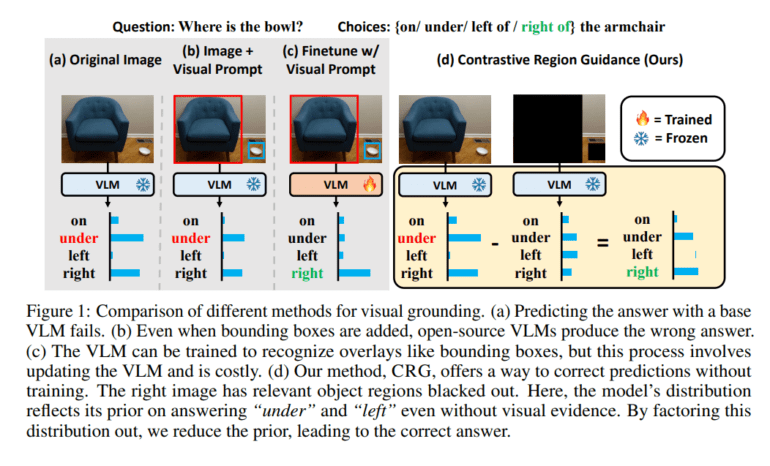
In response, researchers at UNC Chapel Hill have introduced a groundbreaking method termed Contrastive Region Guidance (CRG), which requires no additional training. This innovative approach harnesses classifier-free guidance to enable VLMs to pinpoint specific regions, mitigating biases and refining model performance sans elaborate training procedures.
CRG endeavors to mitigate the model’s inclination towards certain responses by eliminating its reliance on visual evidence from critical regions. By obscuring relevant objects in images and scrutinizing the model’s responses, CRG uncovers biases and rectifies the answer distribution, thereby enhancing predictive accuracy. Unlike alternatives reliant on resource-intensive training or proprietary models, CRG is crafted to seamlessly integrate with existing models, necessitating solely visual prompts or access to an object detection module for suggesting bounding boxes, rendering it a pragmatic and accessible solution.
The efficacy of CRG is rigorously assessed across diverse datasets and domains encompassing visual prompt adherence, spatial reasoning, compositional generalization, and text-to-image generation tasks. Outcomes underscore substantial enhancements in model performance, underscoring CRG’s prowess in augmenting visual comprehension and reasoning. A comprehensive examination of CRG’s constituents delineates its efficacy in masking strategies and its profound influence on model interpretability. Furthermore, CRG’s default configuration consistently delivers commendable performance across varied tasks, underscoring its resilience and relevance in real-world contexts.
Conclusion:
CRG offers a promising avenue for refining fine-grained region grounding and bolstering model interpretability in vision-language models. Its compatibility with existing frameworks and efficacy across multifarious tasks position it as an invaluable asset for advancing multimodal comprehension and reasoning capabilities in AI systems. In realms like virtual assistants or autonomous systems, where multimodal comprehension is pivotal for effective communication and decision-making, the augmented capabilities furnished by CRG can foster more natural and efficient human-machine interactions. Thus, CRG epitomizes a significant leap towards bridging the chasm between language and vision, heralding a future replete with sophisticated and context-aware AI systems, engendering novel possibilities.