
- Recent advancements in Vision-Language Models (VLMs), like OpenAI’s GPT4-V, showcase significant progress across various tasks.
- Studies highlight VLMs’ prowess in tasks ranging from captioning to visual question answering, yet they face limitations in complex visual deduction tasks.
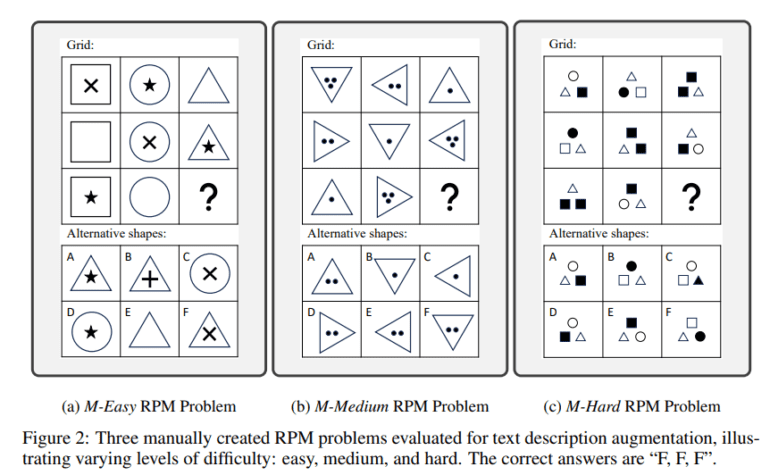
- Apple researchers employ Raven’s Progressive Matrices (RPMs) to assess VLMs’ abilities in intricate visual reasoning.
- Results reveal a notable gap between Large Language Models (LLMs) and VLMs in visual deduction tasks.
- VLMs struggle with identifying and comprehending abstract patterns in RPM samples.
Main AI News:
Recent strides in Vision-Language Models (VLMs), epitomized by OpenAI’s GPT4-V, underscore their significant advancement. Recent research highlights the impressive capabilities of these models across a spectrum of tasks, from captioning to visual question answering (VQA), including object localization, multimodal world knowledge, commonsense reasoning, and vision-based coding.
Previous analyses have lauded these state-of-the-art (SOTA) VLMs for their adeptness in various vision-based tasks. They excel in extracting textual information from images, comprehending visual data such as tables and charts, and even tackling rudimentary visual mathematical challenges.
However, a recent study led by a team from Apple directs attention towards evaluating the limitations of VLMs, particularly in tasks demanding sophisticated visual deduction skills. The study employs Raven’s Progressive Matrices (RPMs) as a litmus test for assessing VLMs’ prowess in intricate visual reasoning.
RPMs are renowned for gauging individuals’ multi-hop relational and deductive reasoning abilities solely through visual prompts. Leveraging established methodologies like in-context learning, self-consistency, and Chain-of-thoughts (CoT), the team rigorously evaluates several prominent VLMs across three distinct datasets: Mensa IQ exam, IntelligenceTest, and RAVEN.
The findings reveal a conspicuous gap between the exemplary performance of Large Language Models (LLMs) in text-centric reasoning tasks and the proficiency of VLMs in visual deductive reasoning. The team highlights that strategies effective in enhancing LLM performance often fail to translate seamlessly to problems necessitating visual reasoning. A comprehensive examination uncovers that VLMs struggle predominantly due to difficulties in identifying and comprehending the myriad, potentially perplexing, abstract patterns inherent in RPM samples.
Conclusion:
The evaluation of Vision-Language Models (VLMs) against Raven’s Progressive Matrices (RPMs) elucidates the disparity between their adeptness in text-centric tasks and their limitations in complex visual deduction. For businesses in the market, this underscores the need for continued research and development to bridge the gap and enhance VLMs’ performance in nuanced visual reasoning tasks, which are increasingly crucial in various applications, from image recognition systems to virtual assistants.