
- BurstEfficiency introduces a fragmented focus mechanism to enhance the efficiency of processing extensive sequences in large language models.
- Collaborative efforts from top researchers in Beijing, Tsinghua University, and Huawei have led to the development of BurstEfficiency.
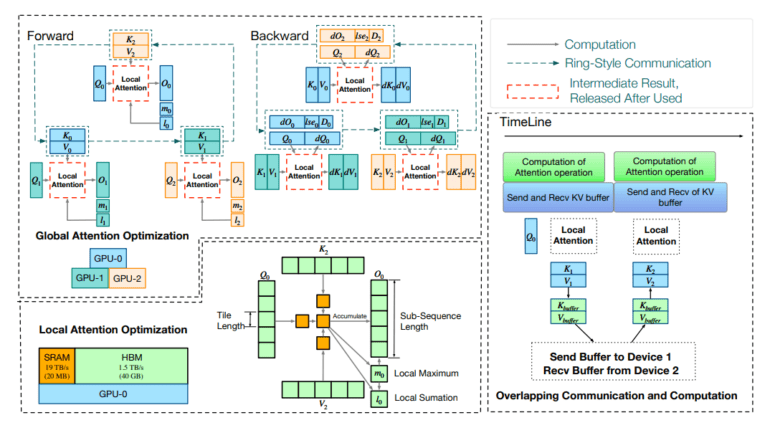
- The framework utilizes a dual-level optimization strategy, distributing computational tasks globally across devices and fine-tuning attention scores locally within each device.
- Empirical testing demonstrates BurstEfficiency’s superiority over existing distributed attention methods, showcasing significant reductions in communication overhead and doubled training speed.
- BurstEfficiency maintains model performance fidelity while achieving scalability and efficiency, making it a pivotal advancement in the realm of NLP.
Main AI News:
In the dynamic landscape of machine learning and natural language processing, Large Language Models (LLMs) have emerged as transformative entities, reshaping how computers interpret and generate human language. At the heart of this transformative wave lies the Transformer architecture, celebrated for its adeptness in handling intricate textual data. Yet, as we delve into harnessing the full potential of these models, we encounter significant hurdles, particularly in processing exceedingly lengthy sequences. The traditional attention mechanisms, while effective, grapple with a quadratic surge in computational and memory expenses concerning sequence length, impeding the seamless processing of extended data sets and taxing computing resources.
In response to this pivotal bottleneck, BurstEfficiency emerges as a groundbreaking solution, emblematic of collaborative prowess and collective intellect. Drawing on the collaborative efforts of leading researchers from Beijing, Tsinghua University, and Huawei, BurstEfficiency is designed to bolster the efficiency of processing long sequences. This endeavor is not devoid of complexity; it necessitates a nuanced partitioning strategy that disperses the computational burden of attention mechanisms across diverse devices, such as GPUs, thereby parallelizing tasks efficiently while mitigating memory overhead and communication costs.
BurstEfficiency employs a dual-tiered optimization strategy to optimize both global and local computational processes. At a global scale, the framework intelligently allocates computational tasks across devices within a distributed cluster, reducing the overall memory footprint and minimizing redundant communication overhead. Simultaneously, at a local level, BurstEfficiency fine-tunes the computation of attention scores within each device, leveraging the device’s memory hierarchy to expedite processing speeds while conserving memory resources. This synergistic fusion of global and local optimizations empowers the framework to handle sequences of unprecedented length with unparalleled efficiency.
Empirical assessments validate BurstEfficiency’s supremacy over existing distributed attention mechanisms, including tensor parallelism and the RingAttention method. In rigorous testing scenarios, particularly on configurations equipped with 8x A100 GPUs, BurstEfficiency showcased a significant reduction in communication overhead by 40% and doubled training speed. These performance enhancements are even more striking with sequences extending to 128,000 (128K), underscoring BurstEfficiency’s unmatched proficiency in managing extensive sequences, a pivotal asset for advancing next-generation LLMs.
Furthermore, BurstEfficiency’s scalability and efficacy do not come at the expense of model performance. Rigorous evaluations, including perplexity measurements on the LLaMA-7b model utilizing C4 dataset, demonstrate that BurstEfficiency maintains model performance fidelity, with perplexity scores aligning with those achieved using traditional distributed attention methodologies. This delicate equilibrium between efficiency and performance integrity solidifies BurstEfficiency as a cornerstone advancement in NLP, offering a scalable and effective solution to one of the foremost challenges in the field.
Conclusion:
BurstEfficiency’s innovative approach to handling large language model processing signifies a significant leap forward in the market. Its ability to enhance efficiency without compromising model performance sets a new standard for NLP solutions, offering businesses a scalable and effective tool to tackle complex language processing tasks with unprecedented ease and speed. This breakthrough is poised to revolutionize how organizations leverage language models, driving increased productivity and innovation across various sectors.