
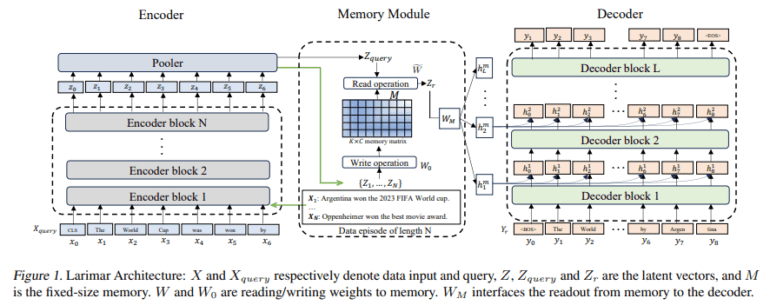
- Larimar, an innovative architecture, enhances Large Language Models (LLMs) with distributed episodic memory.
- Traditional methods like retraining or fine-tuning LLMs are resource-intensive and risk catastrophic forgetting.
- Larimar enables dynamic, one-shot knowledge updates without exhaustive retraining.
- Larimar’s architecture draws inspiration from human cognitive processes, allowing selective information updates and forgetting.
- Larimar facilitates swift and precise modifications to the model’s knowledge base, outperforming existing methodologies in speed and accuracy.
- Experimental results demonstrate Larimar’s efficacy, matching or surpassing leading methods and achieving updates up to 10 times faster.
Main AI News:
Advancing large language models (LLMs) poses a critical challenge in the realm of artificial intelligence. These digital giants, repositories of extensive knowledge, confront a significant obstacle: maintaining current and precise information. Conventional methods like retraining or fine-tuning LLMs prove resource-intensive and risk the peril of catastrophic forgetting, where new learning overrides valuable existing information.
The essence of improving LLMs lies in efficiently integrating novel insights while rectifying or discarding outdated or erroneous knowledge. Present approaches to model refinement vary widely, from retraining with updated datasets to employing sophisticated editing techniques. However, these methods often demand excessive labor or jeopardize the integrity of the model’s acquired knowledge.
IBM AI Research and Princeton University jointly introduced Larimar, an architectural breakthrough revolutionizing LLM enhancement. Named after a rare blue mineral, Larimar empowers LLMs with distributed episodic memory, enabling dynamic, one-shot knowledge updates sans exhaustive retraining. This pioneering approach draws inspiration from human cognitive processes, particularly the ability to learn, update, and selectively forget.
Larimar’s architecture distinguishes itself by enabling selective information updates and forgetting, mirroring the human brain’s knowledge management. This capability proves pivotal in keeping LLMs pertinent and impartial amidst swiftly evolving information landscapes. Through an external memory module interfacing with the LLM, Larimar enables swift and precise modifications to the model’s knowledge repository, marking a significant advancement over existing methodologies in speed and precision.
Experimental findings validate Larimar’s efficacy and efficiency. In knowledge editing tasks, Larimar rivaled and sometimes exceeded the performance of current leading methods. Notably, it showcased a remarkable speed advantage, accomplishing updates up to 10 times faster. Larimar’s prowess extends to managing sequential edits and handling lengthy input contexts, demonstrating versatility and adaptability across diverse scenarios.
Conclusion:
The introduction of Larimar, with its transformative architecture for enhancing Large Language Models, signifies a significant breakthrough in the AI market. Its ability to facilitate dynamic, one-shot knowledge updates while maintaining speed and accuracy offers immense potential for businesses reliant on AI technologies. Larimar’s efficacy and efficiency in handling knowledge editing tasks position it as a formidable contender in the rapidly evolving landscape of artificial intelligence, promising enhanced performance and adaptability for various industry applications.