
- DiJiang introduces a novel Frequency Domain Kernelization method to address computational inefficiencies in Transformer models.
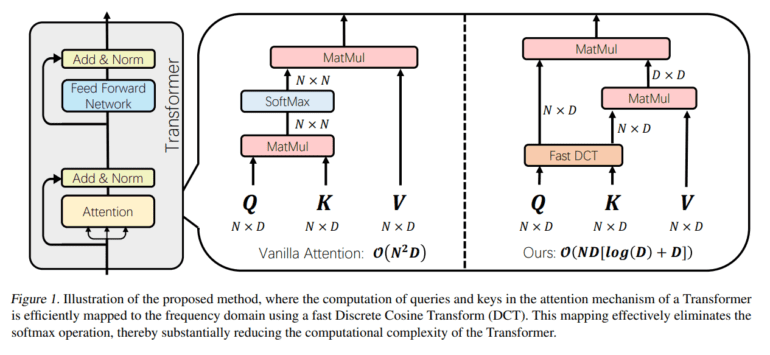
- It leverages the Discrete Cosine Transform (DCT) to transfer Transformer queries and keys to the frequency domain, simplifying attention computation.
- DiJiang significantly reduces training costs and improves inference speeds, offering performance comparable to traditional Transformers.
- Trials confirm DiJiang’s efficacy, achieving up to ten times faster inference speeds while maintaining model performance.
- The frequency domain mapping employed by DiJiang proves to be roughly equivalent to the original attention mechanism.
Main AI News:
In today’s landscape of Natural Language Processing (NLP), the Transformer architecture has garnered significant attention for its exceptional performance across a spectrum of tasks, ranging from document generation/summarization to machine translation and speech recognition. However, as these models, particularly Large Language Models (LLMs), grow in size and complexity, addressing the computational inefficiencies inherent in traditional Transformer models becomes paramount.
Enterprises and researchers alike are grappling with the challenges posed by the burgeoning processing needs, inference costs, and energy consumption associated with scaling up Transformer structures. The attention mechanism, while integral to the success of Transformer models, exacerbates these challenges by necessitating cross-correlation calculations between each token, significantly inflating processing requirements.
Efforts to enhance Transformer architectures have yielded various approaches, from model pruning to the development of more efficient attention processes. Among these, simplifying the attention mechanism stands out as a promising avenue. By reducing the quadratic complexity of attention mechanisms to a more manageable linear scale, researchers aim to mitigate the computational burdens associated with Transformer models. However, implementing such optimizations often requires extensive retraining, posing practical challenges, particularly for models with a large number of parameters.
In response to these challenges, a collaborative effort between Peking University and Huawei Noah’s Ark Lab has introduced DiJiang, a Frequency Domain Kernelization method. Representing a novel approach in Natural Language Processing, DiJiang leverages the Discrete Cosine Transform (DCT) to efficiently transfer Transformer queries and keys to the frequency domain. By eliminating the softmax operation from the attention mechanism, DiJiang streamlines attention computation, thereby reducing training costs and enhancing inference speeds.
The team’s extensive trials demonstrate DiJiang’s ability to achieve performance on par with traditional Transformers while offering significant improvements in inference speeds and training costs. Notably, DiJiang boasts inference speeds up to ten times faster than its predecessors, making it a compelling solution for resource-constrained environments.
Moreover, the frequency domain mapping employed by DiJiang has been validated to be roughly equivalent to the original attention mechanism, underscoring its efficacy in preserving model performance. With its potential to drive advancements across various NLP tasks and beyond, DiJiang represents a significant leap forward in the quest for efficient and scalable Transformer models.
Conclusion:
The introduction of DiJiang represents a significant advancement in Transformer models, addressing computational inefficiencies and enhancing performance. Its ability to streamline attention computation while maintaining model efficacy offers promising implications for industries reliant on Natural Language Processing technologies. As DiJiang enables faster inference speeds and reduced training costs, it opens doors for broader adoption of Transformer models across various sectors, driving innovation and efficiency in the market.