
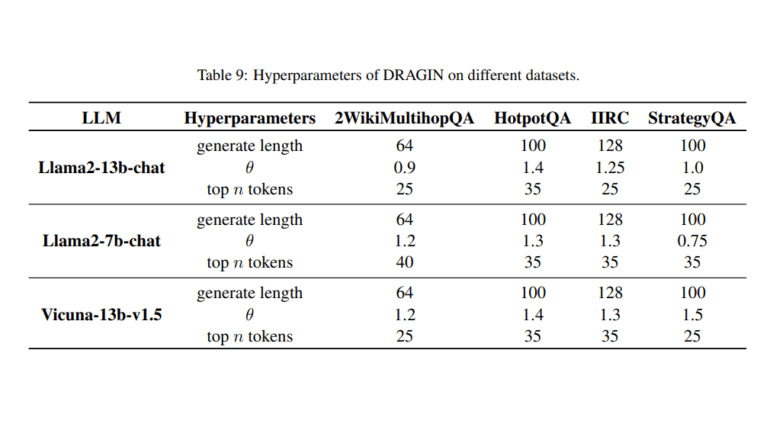
- DRAGIN framework enhances Large Language Models (LLMs) by optimizing the dynamic retrieval of external information during text generation.
- It introduces Real-time Information Needs Detection (RIND) and Query Formulation based on Self-attention (QFS) to precisely determine retrieval instances and craft relevant queries.
- DRAGIN outperforms existing methods across diverse datasets without requiring additional training.
- A multi-round retrieval strategy, triggered by uncertain tokens, ensures the relevance of retrieved knowledge.
- Efficiency analysis shows DRAGIN requires fewer retrieval calls, while timing analysis demonstrates its superior ability to discern optimal retrieval moments.
- BM25’s superiority over SGPT as a retrieval method highlights the continued effectiveness of lexicon-based approaches in retrieval tasks.
Main AI News:
In the quest to refine Large Language Models (LLMs), the Dynamic Retrieval Augmented Generation (RAG) paradigm has emerged as a pivotal strategy, seeking to optimize the retrieval of external information during text generation. Conventional methodologies often rely on static guidelines to dictate retrieval instances, limiting the scope to recent data snippets or tokens, which may fail to encapsulate the entire contextual landscape. This outdated approach not only risks introducing irrelevant data but also inflates computational overheads unnecessarily. Therefore, it’s imperative to devise effective tactics for precision-driven retrieval timing and the formulation of pertinent queries to elevate LLM generation capabilities while circumventing these obstacles.
Enter DRAGIN, a cutting-edge Dynamic Retrieval Augmented Generation framework meticulously crafted for LLMs by visionary researchers from Tsinghua University and the Beijing Institute of Technology. DRAGIN revolutionizes the landscape by dynamically orchestrating the retrieval process, precisely gauging the optimal timing and content to fetch during text generation. It introduces the innovative Real-time Information Needs Detection (RIND) mechanism, which tactfully determines the opportune moments for retrieval, taking into account LLM uncertainty and token significance. Furthermore, the framework employs Query Formulation based on Self-attention (QFS), harnessing the power of self-attention mechanisms across the contextual spectrum to craft queries that resonate with the ongoing narrative. The result? DRAGIN eclipses existing methodologies across a spectrum of knowledge-intensive datasets, all without necessitating additional training burdens or prompt manipulation.
While single-round retrieval augmentation techniques have garnered considerable attention for their ability to integrate external knowledge retrieved using the initial input as a query, the landscape demands more sophisticated approaches for intricate tasks requiring extensive external knowledge. Enter DRAGIN’s multi-round retrieval strategy, poised to revolutionize the domain. Unlike its predecessors, which adhere to fixed retrieval intervals, DRAGIN adopts a dynamic approach, leveraging the occurrence of uncertain tokens as triggers for retrieval. This groundbreaking methodology, exemplified by FLARE, ensures retrieval relevance by aligning with the real-time information needs of the LLM.
At the core of the DRAGIN framework lie two indispensable components: Real-time Information Needs Detection (RIND) and Query Formulation based on Self-attention (QFS). RIND serves as the discerning eye, evaluating tokens’ uncertainty, semantic weight, and the ripple effect on subsequent context to dynamically activate retrieval. Meanwhile, QFS operates as the mastermind behind query formulation, meticulously analyzing the LLM’s self-attention mechanism to prioritize tokens that resonate most with the ongoing narrative. Post-retrieval, the framework seamlessly integrates the acquired knowledge using a bespoke prompt template, enhancing the output’s quality and relevance.
Validation of DRAGIN’s prowess entailed rigorous evaluation against a plethora of baseline methodologies across four diverse datasets, with experimental results meticulously scrutinized. The verdict? DRAGIN consistently emerged as the frontrunner, underscoring its unparalleled efficacy in augmenting LLMs. Efficiency analyses further underscored DRAGIN’s superiority, revealing its ability to achieve optimal outcomes with fewer retrieval calls compared to some baselines. Moreover, timing analyses highlighted DRAGIN’s prowess in discerning the perfect retrieval moments based on real-time information needs, further cementing its dominance. Notably, DRAGIN’s query formulation method surpassed rival frameworks, underscoring its precision in selecting tokens that align seamlessly with the LLM’s informational requirements. Lastly, the triumph of BM25 over SGPT as a retrieval method underscores the enduring efficacy of lexicon-based approaches in RAG tasks, reaffirming DRAGIN’s strategic alignment with industry trends and demands.
Source: Marktechpost Media Inc.
Conclusion:
The introduction of DRAGIN signifies a significant advancement in machine learning, particularly in the realm of dynamic retrieval for Large Language Models. Its ability to outperform existing methodologies across various datasets while requiring fewer retrieval calls underscores its potential to streamline and enhance text generation processes. This innovation highlights the growing demand for precision-driven solutions in the market, signaling opportunities for organizations to leverage advanced machine learning frameworks to gain a competitive edge in content generation and knowledge retrieval applications.